Análise de pertenza do cúmulo M37 - I
Nesta segunda entrada vou facer un análise básico de membresía, é dicir, decidir qué estrelas dunha rexión pertencen a un cúmulo a partir de datos de Gaia.
Análise de pertenza
Introducción
Nesta entrada veremos cómo decidir qué estrelas descargadas dunha rexión pertencen realmente a un cúmulo e cáles son estrelas do campo.
A pasada fin de semana fun co meu telescopio Dobson de 254mm de abertura ao Centro Astronómico de Trevinca aproveitando a lúa nova. As terras de Trevinca teñen posiblemente os mellores ceos de Galicia e do noroeste de España, e sempre merece a pena acercarse para desfutar dun ceo estrelado. O ceo non era o mellor: o fume dos incendios cercanos e algunha nube molestaron, pero aínda así puiden desfrutar de bastantes obxectos. Un deses obxectos que sempre maravilla con prismáticos ou con telescopio é o cúmulo aberto M37 (NGC 2009), na constelación de Auriga. A vista ao telescopio é abraiante; un uaaaau é case inevitable. Desfrutei del durante bastantes minutos, recorrendo o campo pouco a pouco, con distintos aumentos e pódense identificar máis dun cento de estrelas no campo. Agora pretendo aprender algo máis do que vin no ocular. Usando os datos de Gaia vou descargar as estrelas nese campo e decidir cales son realmente do cúmulo e cales son estrelas de fondo nese mesmo campo. Na segunda entrega espero poder facer algunha análise máis e aprender a facer a interpretación astrofísica dos resultados.

M37 é o cúmulo máis rico da constelación de Auriga, con outros dous membros moi interesantes, M36 e M38. Según algunhas fontes é coñecido como “Cúmulo da sal e pementa”. Segundo algúns estudios está a aproximadamente 4.500 anos-luz de distancia. A luz que vin esta fin de semana saiu máis ou menos cando se estaba a levantar o Dolmen de Dombate, a catedral do megalitismo no noroeste de España, e un dos meus lugares predilectos.
Orixe e formación dos cúmulos abertos
Compre explicar brévemente a orixe dun cúmulo aberto. Un cúmulo aberto é un grupo de estrelas que se formaron xuntas a partir da mesma nube molecular de gas e polvo. Coñecense tamén como ‘cúmulos galácticos’ porque atópanse no plano das galaxias espiráis, como a nosa Vía Láctea, onde a formación estelar é máis activa. As estrelas dos cúmulos abertos soen ser xóvenes (< 1.000 millóns de anos de idade), soen estar compostos dende poucas decenas ata uns poucos miles de estrelas. A súa forma é irregular, e as súas estrelas están ligadas gravitatoriamente.
O proceso de formación dun cúmulo aberto empeza cunha gran nube molecular de gas e pó. Dentro desta nebulosa, a gravidade provoca que algunhas zonas se contraigan e colapsen. A medida que estas rexións se comprimen, a presión e a temperatura aumentan, o que desencadena as reaccións de fusión nuclear e o nacemento de novas estrelas. As estrelas recén formadas emiten unha gran cantidade de radiación e ventos estelares que empuxan o gas e o pó restantes cara o exterior. Este proceso disipa a nebulosa de orixen, deixando atrás o grupo de estrelas xóvenes que resultan visibles como un cúmulo aberto.
Debido a que as estrelas dun cúmulo abierto non están tan fortemente unidas pola gravidade como nos cúmulos globulares, a interacción gravitatoria con outras estrelas, nubes de gas ou o propio centro da galaxia fai que, co tempo, o cúmulo se disperse e as súas estrelas se separen.
Análise de pertenza
A análise de pertenza busca separar qué estrelas que realmente pertencen ao cúmulo das estrelas de campo que só están na mesma liña de visión por casualidade. As estrelas do cúmulo son estrelas que naceron xuntas, móvense xuntas e estan á mesma distancia. As estrelas de campo están a diferentes distancias e móvense aleatoriamente; non parecen estar relacionadas entre sí nin co resto das estrelas do cúmulo. Tendo isto en conta, usaremos 3 parámetros para facer a análise de pertenza:
pmRAepmDEC(movementos propios): as estrelas do cúmulo teñen movementos propios moi similares porque naceron da mesma nube molecular e manteñen velocidades similares, o cúmulo móvese coma un todo pola Galaxia.paralaxe: as estrelas do cúmulo están á mesma distancia polo que teñen paralaxes similares.
Para facer a análise usando algoritmos de clustering, podemos escoller entre varios. Un que usei no pasado en entornos de datos empresariais é K-means. Outro que se usa en este tipo de análise é DBSCAN. Vou usar este último por varios motivos: o principal diría que é que DBSCAN non precisa saber a priori cántos grupos ten que facer, se non que o descubre automáticamente. Dado que o propósito desta entrada é amosar unha posible aplicación dos datos de Gaia para analizar cúmulos abertos, non profundizarei moito máis comparando con outros métodos, ou mellorando a implementación deste algoritmo (algo que espero ir facendo máis adiante). Fai uns anos nun proxecto para unha empresa probei PyCaret para validar o resultado con distintos algoritmos, facer o axuste fino dos parámetros e orquestrar todo o pipeline en só 14 liñas de código. Espero revisalo próximamente neste contexto.
Descripción do procesado
O caderno Jupyter está no repositorio do proxecto.
Configuración do entorno
Realizarei o desenrolo usando Python no mesmo entorno virtual que creei na primeira entrada. Só hai que engadir a popular librería scikit-learn.
conda activate cluster_env
pip install scikit-learn
Obtención de datos
Datos básicos dende SIMBAD
Vou reaproveitar parte do código que fixen no primeiro caderno Jupyter. Primeiro, recupero os datos básicos (coordenadas, tamaño…) en SIMBAD. Con este resultado xa temos os datos necesarios para consultar en Gaia (coordenadas e tamaño). Ao executar a consulta en SIMBAD obteño:
Name: M 37Type: OpCRA: 88.077300ºDec: 32.543400ºPmRA: 1.924 (mas/yr)PmDec: -5.648 (mas/yr)galdim_majaxis: 19.299999237060547 (arcmin)galdim_minaxis: 19.299999237060547 (arcmin)Radius: 9.649999618530273 (arcmin)Parallax: 0.666 (mas)
Xa teño as coordenadas e o tamaño. Con iso imos lanzar a consulta á base de datos DR3 de Gaia. Hai que ter en conta neste momento que o tamaño máximo que estou collendo é o que devolve SIMBAD. Quizáis debería ampliar un pouco máis o radio de búsqueda para non deixar fora da consulta estrelas do cúmulo. O campo aparente que vin no ocular do telescopio sí me pareceu superior a 20 minutos de arco.
Consulta á base de datos DR3 de Gaia
Agora imos conectarnos á base de datos de Gaia e lanzar unha consulta a partir dos parámetros obtidos. Nesta ocasión aproveito para facer unha función que espero ir pulindo e reaproveitando máis adiante.
A consulta ADQL xa inclúe varios filtros de calidade:
parallax > 0: recupero só estrelas con paralaxe válidaparallax/parallax_error > 5: filtro só resultados con erro na paralaxe baixopmra_error IS NOT NULLepmdec_error IS NOT NULL: estrelas con erro reportado nos movementos propiosphot_g_mean_mag < 20: estrellas máis brilantes de magnitude 20ruwe < 1.4: estrellas con Renormalised Unit Weight Error <1.4 que garantiza eliminar estrelas binarias, astrometría aceptable…
E lanzo a consulta de forma sinxela, reaproveitando o código anterior. Esta consulta devolve un obxecto astropy.table.Table, que transformo nun Pandas Dataframe co método to_pandas().
A consulta devolve 1.783 estrelas nese campo de visión.
Algunhas visualizacións básicas
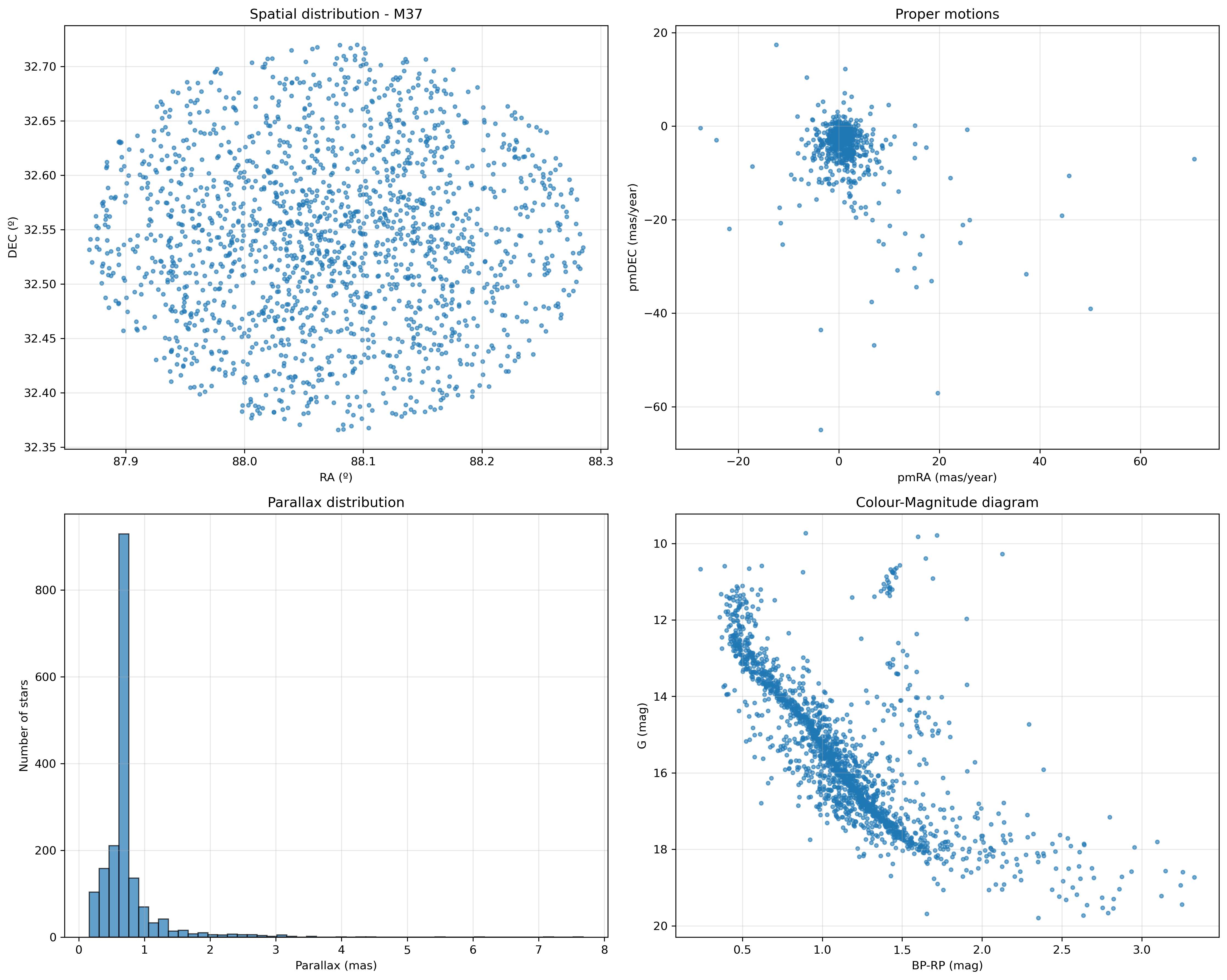
Agora fago algunha gráfica interesante que servirán en futuras análises dos cúmulos. Polo momento só de xeito ilustrativo:
- mapa celeste
- diagrama de movementos propios
- histograma de paralaxes
- diagrama color-magnitude
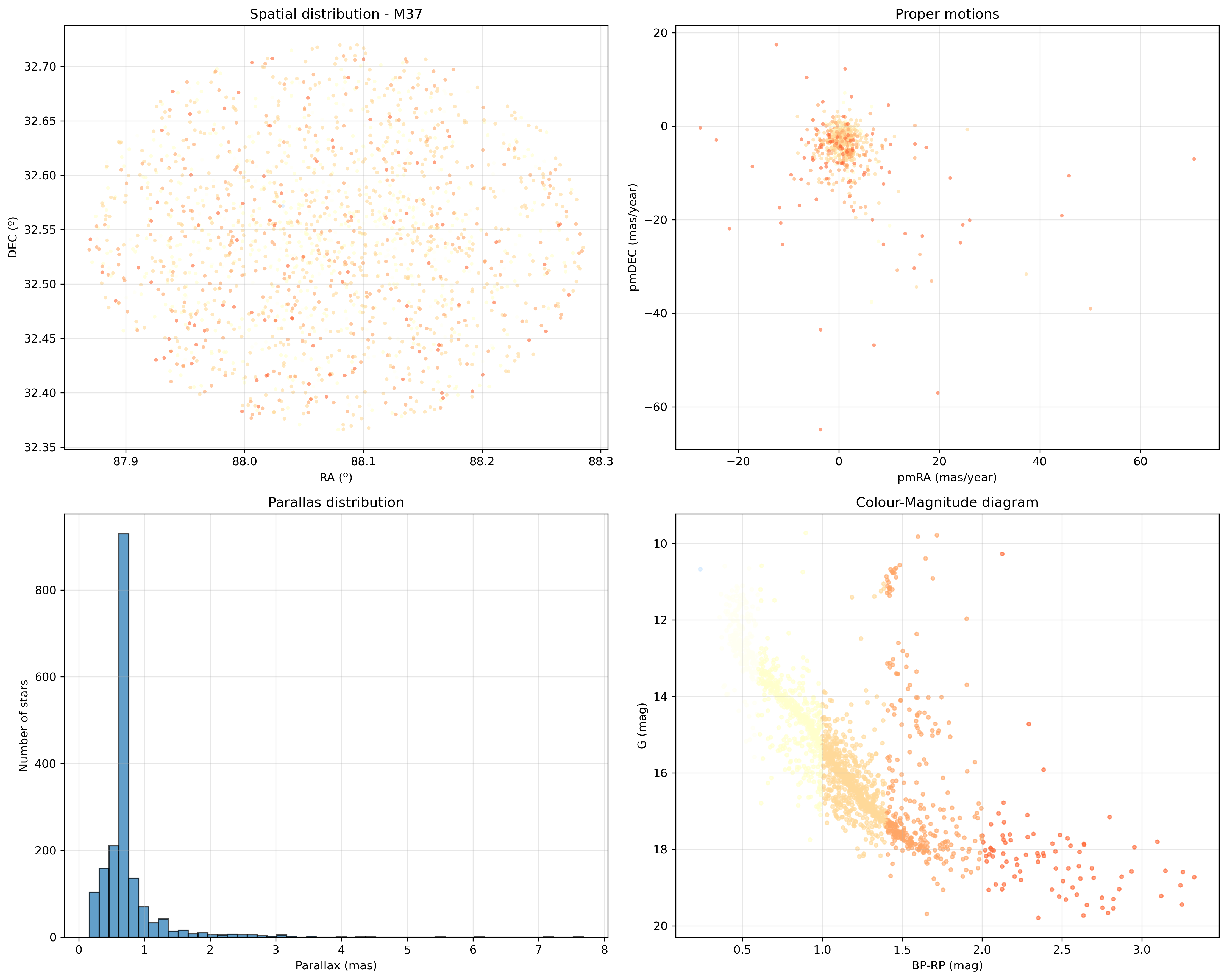
Tamén estiven a probar a conversión dos parámetros BP e RP a cores RGB, de xeito que poderíamos pintar a cor aproximada de cada estrela nestes gráficos:
Na segunda parte profundizarei na información que se pode extraer de cada un destes gráficos.
Análise de membresía
Aquí ven a parte importante do proxecto de hoxe: usar algoritmos de clustering para determinar cales son as estrelas que pertencen ao cúmulo. Como comentaba na introducción, só probarei agora o algoritmo DBSCAN.
Creo unha función para aplicar o algoritmo. Os parámetros que vou usar son os movementos propios e a paralaxe. Como primeira aproximación creo que son os datos máis importantes e centrareime neles.
Seguindo os pasos habituais na aplicacións de algoritmos de clasificación, aplico StandardScaler para escalar os datos e evitar que un dos parámetros inflúa máis que o outro por ter valores maiores. Logo aplico o algoritmo sobre os datos. Usei uns parámetros que atopei en algunha lectura, pero que requerirían un fine tunning para obter os mellores resultados.
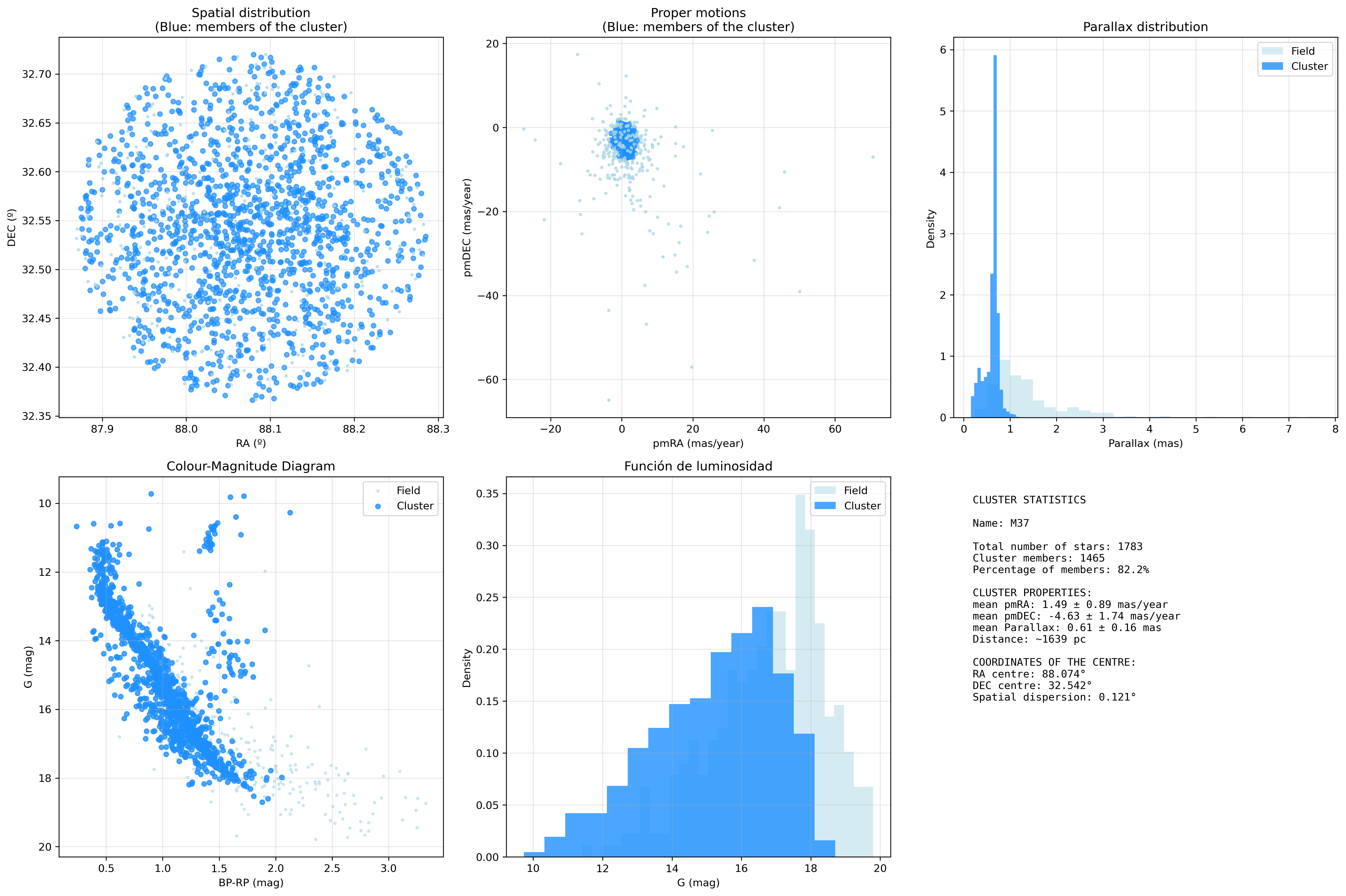
A saída final deste bloque de código é unha nova columna no DataFrame indicando se cada unha das estrelas descargadas é ou non é membro do cúmulo principal. E con isto obteño 1.465 estrelas pertencentes ao cúmulo e 318 identificadas como ruido.
Na seguinte entrada buscarei literatura sobre outras análises deste cúmulo para comparar e ver se a miña aproximación semella correcta.
Resultados
Agora temos un DataFrame con datos das estrelas pertencentes ao cúmulo con varios parámetros, dos que podemos sacar alguns resultados:
RA do centro: 88.074ºDEC do centro: 32.542ºmean pmRA: 1.49 ± 0.89 mas/anomean pmDEC: -4.63 ± 1.74 mas/anomean Parallax: 0.61 ± 0.016mean distance: ~ 1.639 pc
E finalmente, engadimos as mesmas visualizacións anteriores, pero marcando cales son as estrelas membros do cúmulo.
Conclusións e seguintes pasos
O presente exercició é só outra introducción para aprender a descargar e facer análise de datos dun cúmulo aberto cos datos dispoñibles en Gaia DR3. Este tipo de exercicios axudanme no proceso de descubrir todos os datos dispoñibles na base de datos de Gaia, qué atributos son os máis relevantes no estudo dos cúmulos abertos e cómo procesalos. Tamén, aínda que será descrito na parte II deste artigo, descubrir a literatura científica sobre este e outros cúmulos, aprender sobre os parámetros físicos que se teñen estudiado, e cales son as liñas de investigación abertas neste campo.
Con todo isto agardo ir avanzando en adquirir unha base sólida para profundizar nestes eido e desenrolar análises máis complexas.
Sobre a análise de M37, quedan abertos aínda bastantes puntos nos que espero traballar próximamente:
- Atopar literatura científica coa que poder comparar os resultados.
- Realizar fine tunning dos parámetros usados no algoritmo.
- Comparar os resultados con outros algoritmos para realizar a análise de pertenza.
Na seguinte entrada tentarei facer esta investigación, comparar os resultados obtidos con outros estudios publicados, e avanzar na interpretación física dos gráficos e da información relevante que se pode obter.