Análisis de membresía del cúmulo M37
En esta segunda entrada voy a hacer un análisis básico de membresía, es decir, decidir qué estrellas de una región pertenecen a un cúmulo a partir de datos de Gaia.
Análisis de pertenencia
Introducción
En esta entrada veremos cómo decidir qué estrellas descargadas de una región pertenecen realmente la un cúmulo y cáles son estrellas del campo.
El pasado fin de semana fui con mi telescopio Dobson de 254mm de abertura al Centro Astronómico de Trevinca aprovechando la luna nueva. Las tierras de Trevinca tienen posiblemente los mejores cielos de Galicia y del noroeste de España, y siempre merece la pena acercarse para desfutar de un cielo estrellado. El cielo no era el mejor: el humo de los incendios cercanos y alguna nube molestaron, pero aun así pude disfrutar de bastantes objetos. Uno dieras objetos que siempre maravilla con prismáticos o con telescopio es el cúmulo abierto M37 (NGC 2009), en la constelación de Auriga. La vista al telescopio es pasmoso; un uaaaau es casi inevitable. Disfruté de él durante bastantes minutos, recurriendo el campo poco a poco, con distintos aumentos y se pueden identificar más de un ciento de estrellas en el campo. Ahora pretendo aprender algo más del que vine en el ocular. Usando los datos de Gaia voy a descargar las estrellas en ese campo y decidir cuáles son realmente del cúmulo y cuáles son estrellas de fondo en ese mismo campo. En la segunda entrega espero poder hacer algún análisis más y aprender a hacer la interpretación astrofísica de los resultados.

M37 es el cúmulo más rico de la constelación de Auriga, con otros dos miembros muy interesantes, M36 y M38. Según algunas fuentes es conocido como Cúmulo de la sal y pimienta”. Según algunos estudios está a aproximadamente 4.500 años-luz de distancia. La luz que vine este fin de semana saiu más o menos cuando se estaba levantando lo Dolmen de Dombate, la catedral del megalitismo en el noroeste de España, y uno de mis lugares predilectos.
Origen y formación de los cúmulos abiertos
Es necesario explicar brévemente el origen de un cúmulo abierto. Un cúmulo abierto es un grupo de estrellas que se formaron juntas a partir de la misma nube molecular de gas y polvo. Coñecense también como ‘cúmulos galácticos’ porque se encuentran en el plano de las galaxias espiráis, como nuestra Vía Láctea, donde la formación estelar es más activa. Las estrellas de los cúmulos abiertos suenen ser xóvenes (< 1.000 millones de años de edad), suenen estar compuestos desde pocas decenas hasta unos pocos miles de estrellas. Su forma es irregular, y sus estrellas están ligadas gravitatoriamente.
El proceso de formación de un cúmulo abierto empieza con una gran nube molecular de gas y pó. Dentro de esta nebulosa, la gravedad provoca que algunas zonas se contraigan y colapsen. La medida que estas regiones se comprimen, la presión y la temperatura aumentan, lo que desencadena las reacciones de fusión nuclear y el nacimiento de nuevas estrellas. Las estrellas recén formadas emiten una gran cantidad de radiación y vientos estelares que empujan el gas y el pó restantes cara el exterior. Este proceso disipa la nebulosa de orixen, dejando atrás el grupo de estrellas xóvenes que resultan visibles como un cúmulo abierto.
Puesto que las estrellas de un cúmulo abierto no están tan fuertemente unidas por la gravedad como nos cúmulos globulares, la interacción gravitatoria con otras estrellas, nubes de gas o el propio centro de la galaxia hace que, con el tiempo, el cúmulo se disperse y sus estrellas se separen.
Análisis de pertenencia
El análisis de pertenencia busca separar qué estrellas que realmente pertenecen al cúmulo de las estrellas de campo que solo están en la misma línea de visión por casualidad. Las estrellas del cúmulo son estrellas que nacieron juntas, se mueven juntas y estan a la misma distancia. Las estrellas de campo están la diferentes distancias y se mueven aleatoriamente; no parecen estar relacionadas entre sí ni con el resto de las estrellas del cúmulo. Teniendo esto en cuenta, usaremos 3 parámetros para hacer el análisis de pertenencia:
pmRAypmDEC(*movimientos propios**): las estrellas del cúmulo tienen movimientos propios muy similares porque nacieron de la misma nube molecular y mantienen velocidades similares, el cúmulo se mueve como uno todo por la Galaxia.paralaje: las estrellas del cúmulo están a la misma distancia por lo que tienen paralajes similares.
Para hacer el análisis usando algoritmos de clustering, podemos escoger entre varios. Un que usé en el pasado en entornos de datos empresariales es K-means. Otro que se usa en este tipo de análisis es DBSCAN. Voy a usar este último por varios motivos: el principal diría que es que DBSCAN no precisa saber a priori cántos grupos tiene que hacer, si no que lo descubre automáticamente. Dado que el propósito de esta entrada es mostrar una posible aplicación de los datos de Gaia para analizar cúmulos abiertos, no profundizare mucho más comparando con otros métodos, o mejorando la implementación de este algoritmo (algo que espero ir haciendo más adelante). Hace unos años en un proyecto para una empresa probé PyCaret para validar el resultado con distintos algoritmos, hacer el ajuste fino de los parámetros y orquestar todo el pipeline en solo 14 líneas de código. Espero revisarlo próximamente en este contexto.
Descripción del procesado
El cuaderno Jupyter está en el repositorio del proyecto.
Configuración del entorno
Realizaré el desarrollo usando Python en el mismo entorno virtual que creé en la primera entrada. Sólo hay que añadir la popular librería scikit-learn.
conda activate cluster_env
pip install scikit-learn
Obtención de datos
Datos básicos desde SIMBAD
Voy a reutilizar parte del código que hice en el primer cuaderno Jupyter. Primero, recupero los datos básicos (coordenadas, tamaño…) en SIMBAD. Con este resultado ya tenemos los datos necesarios para consultar en Gaia (coordenadas y tamaño). Al ejecutar la consulta en SIMBAD obtengo:
Name: M 37Type: OpCRA: 88.077300ºDec: 32.543400ºPmRA: 1.924 (mas/yr)PmDec: -5.648 (mas/yr)galdim_majaxis: 19.299999237060547 (arcmin)galdim_minaxis: 19.299999237060547 (arcmin)Radius: 9.649999618530273 (arcmin)Parallax: 0.666 (mas)
Ya tengo las coordenadas y el tamaño. Con eso vamos a lanzar la consulta a la base de datos DR3 de Gaia. Hay que tener en cuenta en este momento que el tamaño máximo que estoy cogiendo es lo que devuelve SIMBAD. Quizáis debería ampliar un poco más el radio de búsqueda para no dejar había sido de la consulta estrellas del cúmulo. El campo aparente que vine en el ocular del telescopio sí me pareció superior a 20 minutos de arco.
Consulta a la base de datos DR3 de Gaia
Ahora vamos a conectarnos a la base de datos de Gaia y lanzar una consulta a partir de los parámetros obtenidos. En esta ocasión aprovecho para crear una función que espero ir puliendo y reutilizando más adelante.
La consulta ADQL ya incluye varios filtros de calidad:
parallax > 0: recupero sólo estrelas con paralaje válidaparallax/parallax_error > 5: filtro sólo resultados con error en paralaje bajopmra_error IS NOT NULLypmdec_error IS NOT NULL: estrellas con error reportado en los movimientos propiosphot_g_mean_mag < 20: estrellas máis brilantes de magnitud 20ruwe < 1.4: estrellas con Renormalised Unit Weight Error <1.4 que garantiza eliminar estrellas binarias, astrometría aceptable…
Lanzo una consulta de forma sencilla, reutilizando el código anterior. Esta consulta devuelve un objeto astropy.table.Table, que transformo en un Pandas Dataframe con el método to_pandas().
La consulta devuelve 1.783 estrellas.
Algunas visualizaciones básicas
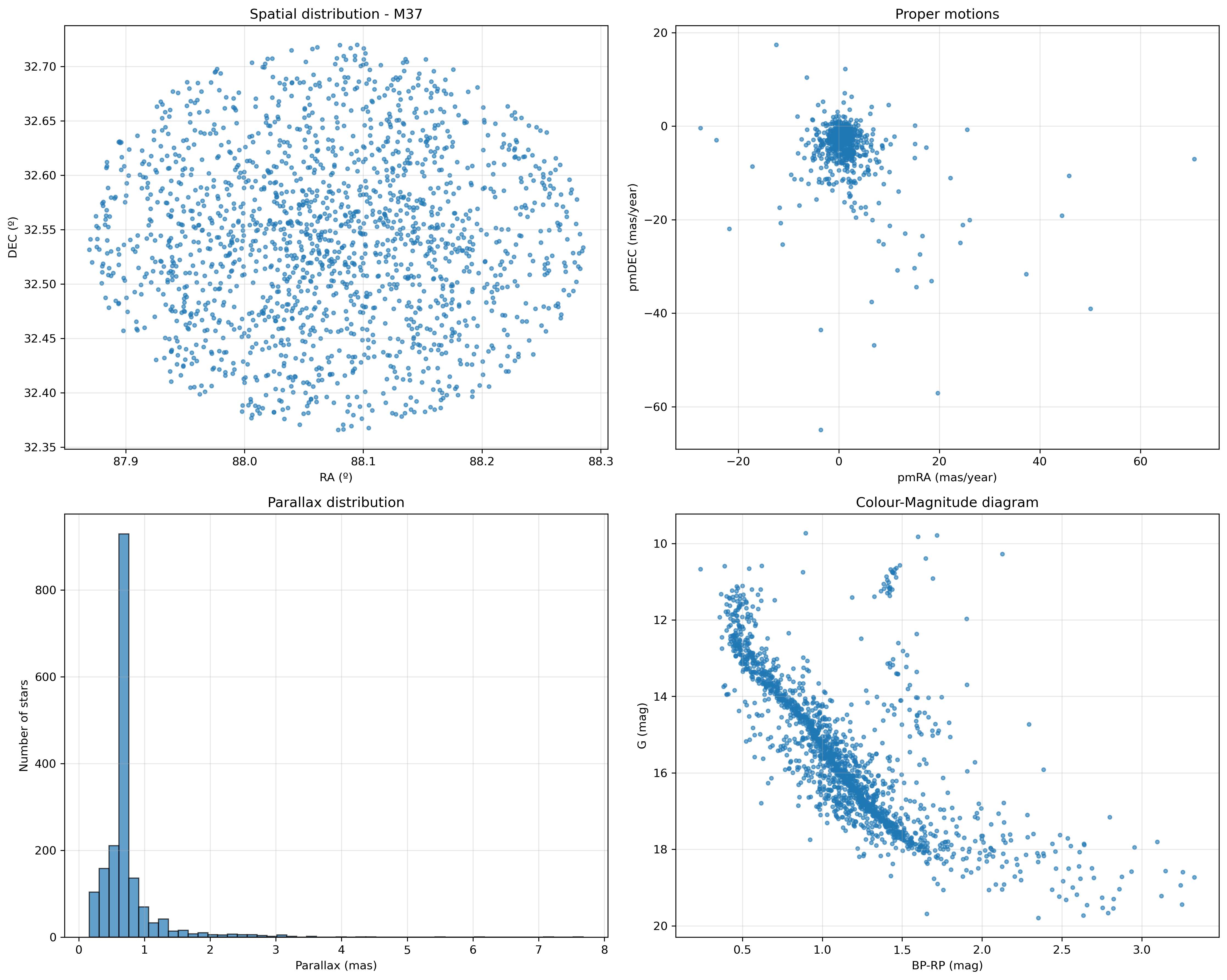
Ahora hago alguna gráfica interesante que servirán en futuros análisis de los cúmulos. Por el momento solo de manera ilustrativa:
- mapa celeste
- diagrama de movimientos propios
- histograma de paralajes
- diagrama color-magnitud
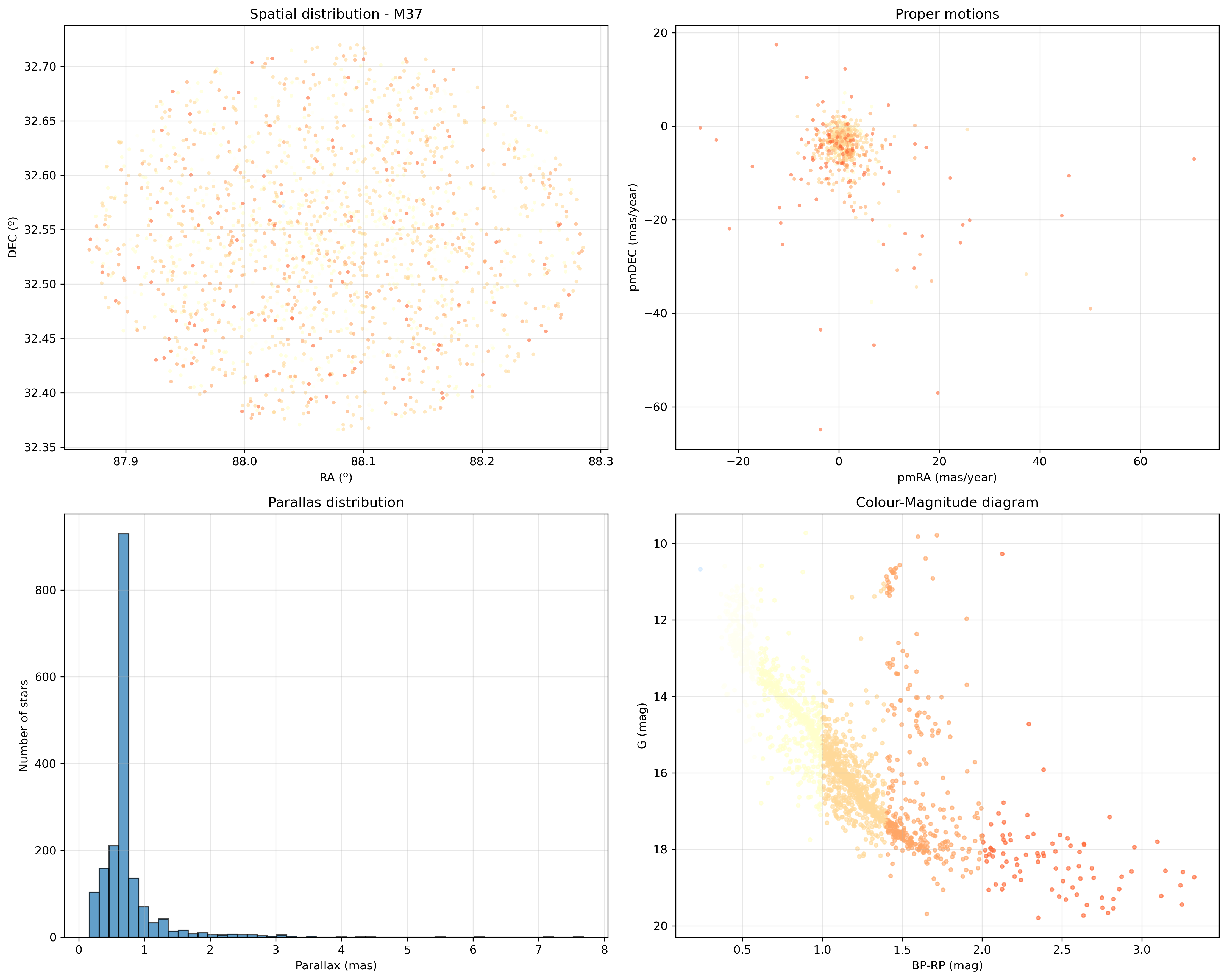
También probé la conversión de los parámetros BP y RP a colores RGB, de manera que pudiéra pintar el color real de cada estrella en estos gráficos y ver el resultado.
En la segunda parte de esta entrada profundizaré en la información que se puede extraer de cada uno.
Análisis de pertenencia
Aquí viene la parte importante del proyecto de hoy: usar algoritmos de clustering para determinar cuáles son las estrellas que pertenecen al cúmulo. Como comentaba en la introducción, solo probaré ahora el algoritmo DBSCAN.
Creo una función para aplicar el algoritmo. Los parámetros que voy a usar son los movimientos propios y el paralaje. Como primera aproximación creo que son los datos más importantes y me centraré en ellos.
Siguiendo los pasos habituales en la aplicaciones de algoritmos de clasificación, aplico StandardScaler para escalar los datos y evitar que uno de los parámetros influya más que lo otro por tener valores absolutos mayores. Luego aplico el algoritmo sobre los datos. Usé unos parámetros que encontré en alguna lectura, pero que requerirían un fine tunning para obtener los mejores resultados.
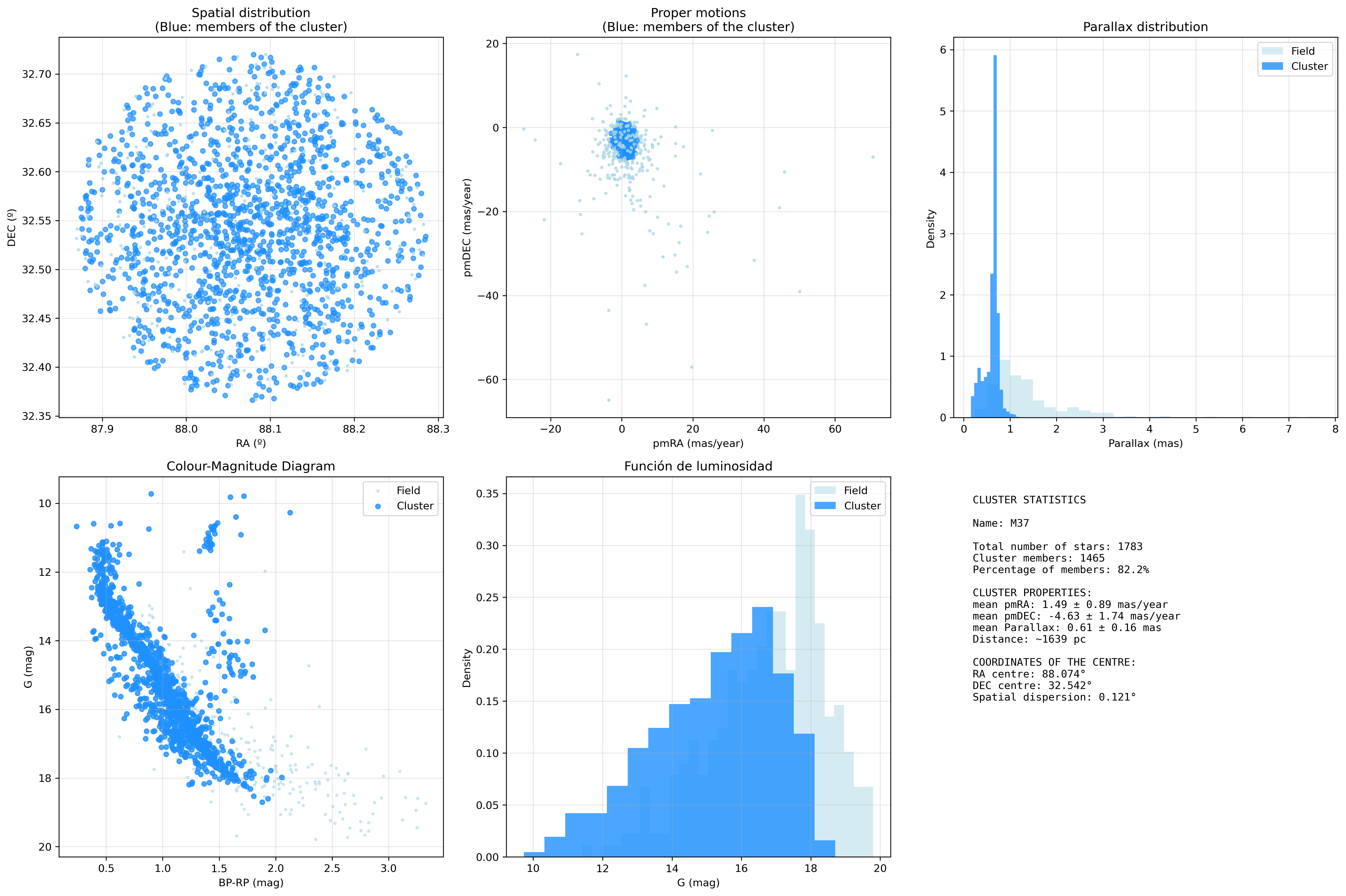
La salida final de este bloque de código es una nueva columna en el DataFrame indicando si cada una de las estrellas descargadas es o no es miembro del cúmulo principal. Y con esto obtengo 1.465 estrellas pertenecientes al cúmulo y 318 identificadas como ruido.
En la siguiente entrada buscaré literatura sobre otros análisis de este cúmulo para comparar y ver si mi aproximación parece correcta.
Resultados
Ahora tenemos un DataFrame con datos de las estrelas pertenecientes al cúmulo con varios parámetros, de los que podemos sacar algunos resultados:
RA del centro: 88.074ºDEC del centro: 32.542ºmean pmRA: 1.49 ± 0.89 mas/añomean pmDEC: -4.63 ± 1.74 mas/añomean Parallax: 0.61 ± 0.016mean distance: ~ 1.639 pc
Y finalmente, añadimos las mesmas visualizaciones anteriores, pero marcando cuales son las estrellas miembros del cúmulo.
Conclusiones y siguientes pasos
El presente ejercicio es sólo otra introducción para aprender a descargar y hacer análisis de datos de un cúmulo abierto con los datos disponibles en Gaia DR3. Este tipo de ejercicios me ayudan en el proceso de descubrir todos los datos disponibles en la base de datos de Gaia, qué atributos son los más relevantes en el estudio de los cúmulos abiertos y cómo procesarlos. También, aunque será descrito en la parte II de este artículo, descubrir la literatura científica sobre este y otros cúmulos, aprender sobre los parámetros físicos que se han estudiado, y cuáles son las líneas de investigación abiertas en este campo.
Con todo esto espero ir avanzando en adquirir una base sólida para profundizar en estos campo y desenrollar análisis más complejos.
Sobre el análisis de M37, quedan abiertos aún bastantes puntos en los que espero trabajar próximamente:
- Encontrar literatura científica con la que poder comparar los resultados.
- Realizar fine tunning de los parámetros usados en el algoritmo.
- Comparar los resultados con otros algoritmos para realizar el análisis de pertenencia.
En la siguiente entrada intentaré hacer esta investigación, comparar los resultados obtenidos con otros estudios publicados, y avanzar en la interpretación física de los gráficos y de la información relevante que se puede obtener.