Análisis de pertenencia del cúmulo abierto M37 - II DBSCAN
Continuamos con el análisis de pertenencia para las estrellas del cúmulo M37, probando varios algoritmos, ajustando parámetros y comparando los resultados con la literatura disponible. En esta entrada nos centraremos en perfeccionar el análisis con DBSCAN y analizar sus resultados.
Esta es una entrada larga, que incluye conceptos sobre evolución estelar y sobre los propios cúmulos.
Análisis de pertenencia
Introducción
En la primera parte expliqué cómo hacer un análisis básico de pertenencia a un cúmulo abierto a partir de los datos descargados de Gaia para una región dada. En las siguientes entradas de esta serie vamos a hacer un análisis de pertenencia mucho más riguroso, usando varios algoritmos de clasificación no supervisada (DBSCAN, HDBSCAN y GMM), comparando los resultados entre ellos y con publicaciones disponibles. Los 3 métodos son ampliamente utilizados en distintos artículos que abordan el problema de la pertenencia en cúmulos abiertos. Otros artículos usan también otros algoritmos de clasificación supervisada como K-means, pero yo decidí descartarlos por el momento, pues requiere de tener datos ya etiquetados para lo entrenamento del modelo. Por el momento haré un análisis con 3 dimensiones disponibles en Gaia: paralaje y movimientos propios en ascensión recta y declinación.
Buscando literatura encuentro que M37 es un cúmulo bastante estudiado y que me permite comparar los resultados obtenidos y validar mi proyecto.
Como en los artículos previos, los datos que usaré son descargados de Gaia DR3 (Gaia Collaboration, Vallenari, La., et al. (arXiv) (ADS)). La base de datos Gaia DR3 es la tercera release de datos y proporciona unos 1.81 mil millones de objetos, de los cuales 1.47 mil millones tienen los datos completos de astrometría y fotometría. En particular, los datos de paralaje y movimientos propios con altísima precisión serán usados aquí para el análisis de pertenencia.
La descripción de algunos de los datos de Gaia es importante resaltarla en algún momento de esta serie de artículos, y probablemente sea merecedor de un artículo exclusivo.
Según la literatura encontrada o la propia página de SIMBAD para M37 los datos principales del cúmulo son:
| RA (α) | Dec (δ) | pmra (μ_α) (mas/yr) | pmdec (μ_δ) (mas/yr) | parallax (π) (mas) |
|---|---|---|---|---|
| 88.074 | 32.545 | 1.924 ± 0.06 | -5.648 ± 0.05 | 0.666 ± 0.07 |
De estos datos partiré para hacer la descarga y filtrado de datos de Gaia y para comparar los datos obtenidos como resultado.
Descarga de datos de Gaia DR3
Para la descarga de datos de Gaia DR3 sigo el mismo método que ya usé anteriormente con los siguientes parámetros:
RA (α): 88.074Dec (δ): 32.545search_radius:1.5º
Con la elección de 1.5º pretendo recuperar los datos no solo de estrellas del centro del cúmulo, senon también las estrellas de la corona cercana e incluso alguna de las estrellas evaporándose. Un radio aun más grande podría ser adecuado para un estudio más completo que incluya las estructuras de marea del cúmulo. No lo haré en este momento, pero sí queda anotado como una funcionalidad a posibilidad de seleccionar el radio de búsqueda para incorporar en versiones posteriores del código.
También se incluyen los filtros estándar sobre los datos de Gaia:
FROM gaiadr3.gaia_source
WHERE 1=CONTAINS(
POINT('ICRS', ra, dec),
CIRCLE('ICRS', {cluster_ra}, {cluster_dec}, {search_radius})
)
AND parallax IS NOT NULL
AND parallax/parallax_error > 5
AND pmra IS NOT NULL
AND pmdec IS NOT NULL
AND ruwe < 1.4
AND phot_g_mean_mag < 20
Con estos datos la consulta a Gaia devuelve 53.109 estrellas, con esta estadística básica:
Número de estrellas: 53109Paralaje medio: 0.84 ± 0.88 masμ_α medio: 1.19 ± 5.32 mas/yrμ_δ medio: -4.55 ± 7.60 me las/yr
Filtrado de los datos descargados
La consulta devuelve más de 53000 estrellas, un volumen elevado y seguramente la mayoría no pertenecen al cúmulo. Aquí decidí aplicar un filtro antes de aplicar los algoritmos de clasificación. Está bastante claro que en esta consulta hay muchas estrellas en el mismo campo de visión que no pertenecen al cúmulo. Pensemos ahora que el cúmulo son precisamente estrellas que nacieron en la misma zona y que se mueven más o menos del mismo modo (con cierta dispersión, por supuesto). Para reducir el procesamiento posterior e ir eliminando errores, voy a filtrar los datos a partir del conocimiento que ya existe sobre el cúmulo M37: los valores de paralaje y de los movimientos propios de los miembros del cúmulo tienen que estar en un valor cercano al ya conocido. Se filtramos los datos cerca de esos valores conocidos y eliminamos los restantes, iremos afinando, reduciendo el coste computacional posterior y reduciendo errores. ¿Cómo decidir los valores para filtrar? Considero el siguiente: cuando decido un rango para lo filtrado debo tener en cuenta que la Dispersión Total nos valores de los miembros estará compuesta por:
Dispersión total = dispersión intrínseca + errores de medida
Dispersión instrínseca: no todas las estrellas del cúmulo se mueven igual. Hay una dispersión de velocidades que se puede deber principalmente a las interacciones gravitatorias internas entre sí, encuentros cercanos entre dos estrellas, estrellas binarias que crean movimientos al orbitar entre ellas o estrellas que escapan del cúmulo con velocidades anómalas. Estas dispersiones en las velocidades se puede estimar aproximadamente en:
- Cúmulos jóvenes (<100 Myr): σ_v ~ 0.5-1.5 km/s
- Cúmulos intermedios (100-500 Myr): σ_v ~ 0.3-1.0 km/s
- Cúmulos viejos (>500 Myr): σ_v ~ 0.2-0.8 km/s
La edad estimada de M37 es de 500Myr, y escogeré un rango algo amplio. Si incluyo estrellas de más, espero que los algoritmos de clustering filtren las estrellas que no pertenezcan. El rango fijado en el filtro es de σ_v ~ 0.5-1.0 km/s, que se puede traducir a mas/yr con la fórmula:
μ [mas/yr] = (v_transversal [km/s] / d [pc]) × 211.09La distancia estimada de M37 es de 1500pc, con lo que los valores del rango serían:
σ_μ = (0.5 km/s / 1500 pc) × 211.09 = 0.070 mas/yr (mínimo) σ_μ = (1.0 km/s / 1500 pc) × 211.09 = 0.141 mas/yr (máximo)Es decir, añadiría una dispersión intrínseca σ_μ ~0.07 - 0.14 mas/yr.
Error de medida de Gaia Los errores de medida de Gaia tienen que ver con varios factores: magnitud (estrellas más débiles tienen mayor error), regiones del cielo con mayor o menor densidad de estrellas, número de observaciones… Los errores típicos por magnitud son:
Magnitud G Error Descripción G < 14 error_μ ~ 0.02-0.05 mas/yr estrellas brillantes 14 < G < 16 error_μ ~ 0.05-0.15 mas/yr estrellas intermedias 16 < G < 18 error_μ ~ 0.15-0.50 mas/yr estrellas débiles De nuevo, voy a escoger un rango amplio: σ_error ~ 0.10-0.25 mas/yr teniendo en cuenta que las estrellas que más contribuyen al cúmulo están en el rango G=12-17.
A la hora de combinar errores:
σ_total = √(σ_intrínseca² + σ_error²)
así que la dispersión total esperada es de ~0.2 - 0.3 mas/yr
- Margen de seguridad En la práctica hay otras causas que pueden afectar a la dispersión del cúmulo. Una regla empírica robusta es usar ±3σ a ±5σ alrededor del valor esperado:
±3σ → captura 99.7% de una distribución normal ±4σ → captura 99.99% ±5σ → muy conservadorPrefiero ser conservador, y usar 5σ, lo que nos daría para μ_α y para μ_δ un margen de σ_seguridad 1.25mas/yr.
En global, me quedo con un rango en los movimientos propios de rango μ_α de 0.7 a 3.0mas/yr y rango μ_δ de -7.0 a -4.0
- Límites en el paralaje Para filtrar el paralaje y quedarnos dentro de unos límites razonables que incluyan a las estrelas del cúmulo y minimicen las estrellas de campo, tengo en cuenta los valores estimados en la literatura. El paralaje estimado de M37 es de 0.666mas (distancia ~1500pc). La dispersión típica de un cúmulo abierto está entre los 10-50pc, que a una distancia aproximada de 1500pc correspondería a un margen de paralaje de ±0.01-0.05 mas. Añadimos un margen de error en la medida de Gaia (~0.05-0.10mas). Así que siendo conservadores, para no excluir estrellas del cúmulo en el filtro, establezco un rango en paralaxe de 0.50-0.85mas.
Al aplicar estos límites sobre los datos descargados de Gaia, obtengo:
- `Número de estrellas`: **3377**
- `Paralaje medio`: **0.67 ± 0.08 mas**
- `μ_α medio`: **1.86 ± 0.45 mas/yr**
- `μ_δ medio`: **-5.50 ± 0.62 mas/yr**
Y como último paso hago una normalización de los datos, para llevarlos todos a una escala similar y que unos valores más altos en uno de los parámetros no dominen el análisis.
Análisis de pertenencia con DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) es un algoritmo que agrupa puntos basándose en su densidad local. El algoritmo tiene dos parámetros principales:
eps: la distancia máxima entre dos puntos para considerarlos vecinos.mí_samples: el número mínimo de puntos necesarios para formar un grupo denso.
DBSCAN es especialmente bueno para cúmulos porque:
- No asume que los grupos tienen forma esférica
- Puede identificar puntos como “ruido” (estrellas del campo)
- No necesita saber de antemano cuantos cúmulos hay
Lo cierto es que no encontré por el momento un método para decidir cuáles son los valores óptimos para cada cúmulo, porque sí afectan al resultado del algoritmo, y no parecen comportarse igual en cada cúmulo. Para mi caso, después de varias pruebas me quedo con estos valores:
eps: 0.3min_samples: 20
Con estos valores obtengo los seguintes resultados:
Número de cúmulos identificados: 1Estrellas clasificadas como ruido (campo): 1773Estrellas clasificadas en el cúmulo principal1689Paralaje: 0.67±0.05masμ_α: 1.88±0.15mas/yrμ_δ: -5.62±0.15mas/yr
Esos valores son extraordinariamente coincidentes con otros estudios e con los propios datos de SIMBAD. Así, Cantat-Gaudin et al. (2018) obtienen Paralaxe: 0.66mas, μ_α:1.92mas/yr e μ_δ: -5.64. M Noormohammadi, M Khakian Ghomi, A Javadi (2024) obtinen Paralaxe: 0.67 ± 0.08mas, μ_α:1.87 ± 0.09mas/yr e μ_δ: −5.62 ± 0.06mas/yr usando una combinación de DBSCAN y GMM.
Análisis de resultados
Ahora analizaré los resultados obtenidos, lo que me permite aprender en detalle muchos de los conceptos físicos que hay detrás.
Comienzo con algunas gráficas para ver el resultado:
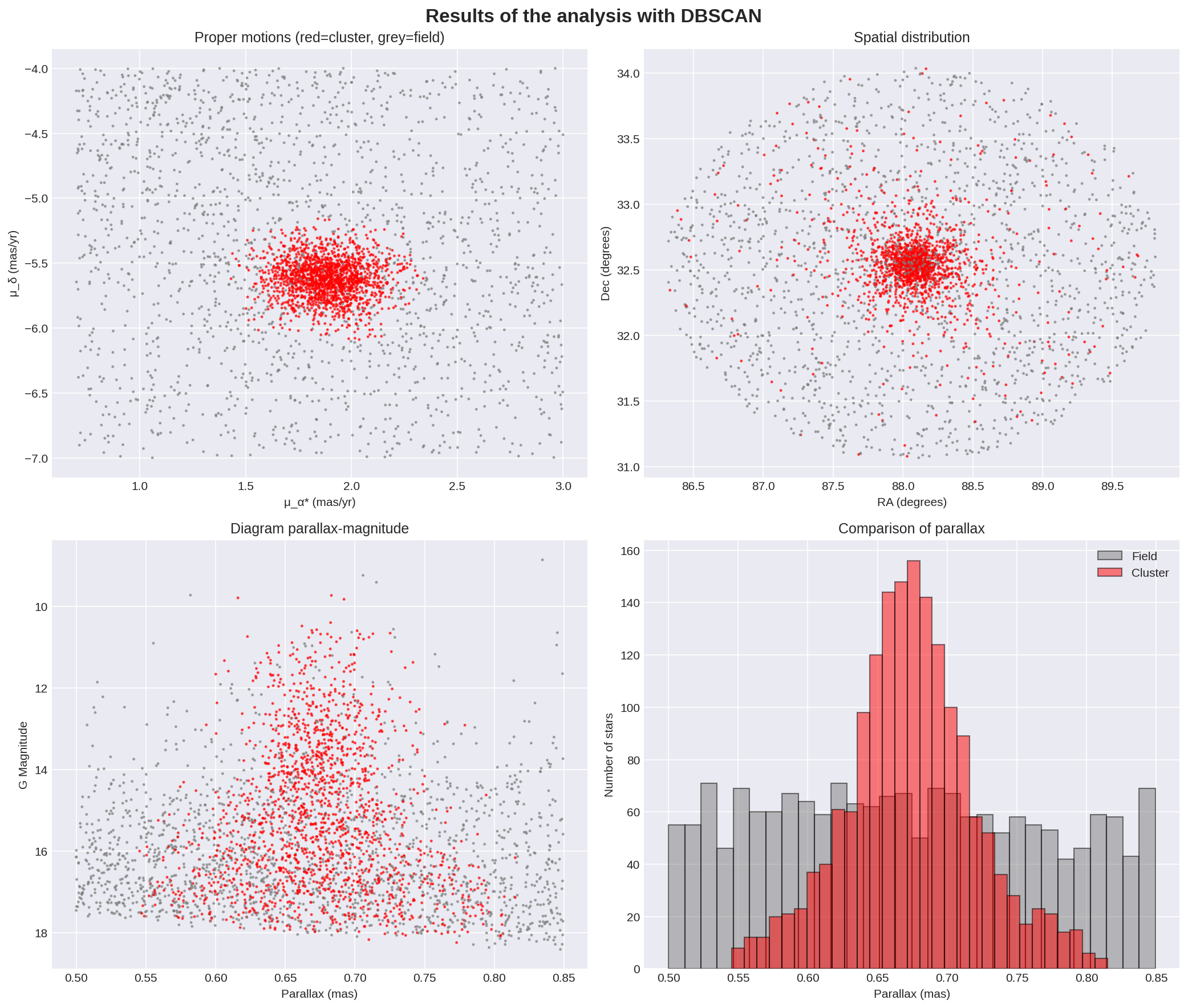
Estos 4 gráficos permiten verificar si la clasificación es consistente con el conocimiento actual del cúmulo o se hay algún dato que haga replantexar los parámetros del algoritmo.
1. Diagrama de movimientos propios
El diagrama de movimientos propios es quizáis el más importante: las estrellas del cúmulo nacieron juntas y viajan juntas por el espacio, por lo que formarán un grupo compacto en este diagrama. El campo estelar está compuesto por estrellas de diferentes edades, distancias y órbitas galácticas, por lo que aparecerá desparramado. La separación clara entre estos dos grupos es la que hace posible a análisis de pertenencia. En el diagrama generado se ve claramente como DBSCAN identificó correctamente el núcleo del cúmulo y sin contaminiación significativa en el espacio cinemático. El cúmulo en rojo es muy compacto centrado en (μ_α* ≈ 1.9, μ_δ ≈ -5.6). Las estrellas de campo en gris están desparramadas por todo el espacio. No hay solapamiento entre ambos.
2. *Distribución espacial**
La distribución que se muestra en la gráfica generada es consistente con lo esperado: un núcleo central centrado en ≈(88.0°, 32.7°) y radio ≈0.3-0.4 grados. No se aprecian subestructuras ni múltiples núcleos.
3. Diagrama Paralaje-Magnitud
En este diagrama se muestra la relación entre la magnitud absoluta de los miembros vs distancia (paralaje). Dado que las estrellas del cúmulo están a la misma distancia, esperamos ver una columna vertical centrada en 0.67mas con estrellas de todas las magnitudes. En la parte superior estarían las estrellas más brilantes (gigantes, estrellas masivas) y en la parte inferior las estrellas más débiles (enanas de baja masa). Los datos observados son de nuevo coherentes con el esperado: hay una columna centrada en 0.67mas con un ancho de ±0.03-0.04 mas aproximadamente. A partir de estos datos se podría obtener la profundidad del cúmulo, que puede estar en el entorno de los 50pc.
4. *Histograma de paralajes**
Este diagrama muestra el nº de estrellas vs paralaje. Esperaría tener una distribución gaussiana centrada en 0.67mas, pues las estrellas del cúmulo deberían estar todas a la misma distancia aproximadamente, y con más concentración en el centro del cúmulo. Lo que vemos es un pico central en ≈0.67mas, con una altura de ≈155 estrellas/bin. La forma es una gaussiana y el ancho a media altura es de ≈0.04mas (0.65-0.69 mas).
5. Diagrama Color Magnitud (CMD)
Este diagrama es clave para todo el análisis: el diagrama color magnitud. En este diagrama representamos las estrellas identificadas como miembros del cúmulo mostrando la magnitud absoluta (luminosidad) frente al tipo espectral. La luminosidad, o magnitud absoluta es un dato que obtenemos directamente del campo phot_g_mean_mag (magnitud absoluta en la banda G) de Gaia. En el eje x del diagrama usamos bp-rp, obtenidos a partir de los campos phot_bp_mean_mag y phot_rp_mean_mag de Gaia (magnitudes absolutas en las bandas rp y bp). Un BP-RP pequeño indica que es una estrella azul, muy caliente (≈10,000K), mientras un BP-RP grande indica que es una estrella azul y fría (≈3,000K)
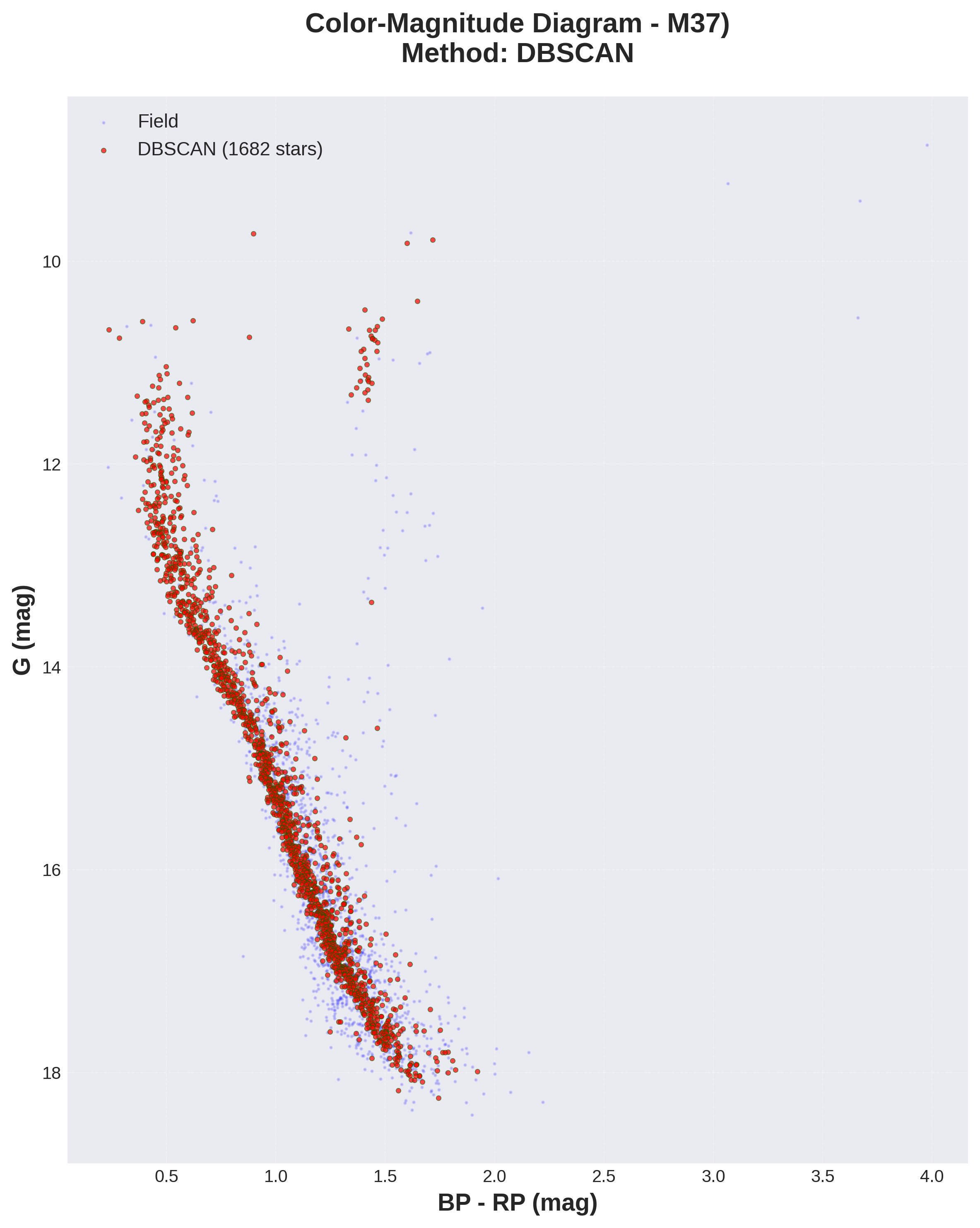
Este diagrama proporciona muchísima información, que tratare de explicar en varios puntos:
5.1. Secuencia principal estrecha y contínua La línea de la secuencia principal parece correcta. desde un BP-RP ≈ 0.5 y G ≈ 12 (corresponde a estrellas muy masivas y calientes, azules) hasta BP-RP ≈ 2.0 y G ≈ 18 (enanas de baja masa, frías y rojas). La trayectoria no presenta saltos, y además es muy estrecha (baja dispersión). Esa baja dispersión es indicador de que las estrellas identificadas tienen la misma edad y la misma metalicidade. ¿Por qué?
Aquí voy a introducir varios conceptos. La posición de una estrella en el diagrama CMD depende básicamente de su masa. Y la masa de la estrella marca la duración en la secuencia principal: las estrellas más masivas, debido a la mayor presión gravitatoria en el núcleo queman el hidrógeno a mayor ritmo que las estrellas menos masivas. Esta duración ven determinada por el ritmo a lo que quema el combustible. La vida en la secuencia principal de una estrella se puede aproximar con esta fórmula: t = 1010 (M/M☉)-2.5.
| Masa | Tiempo en SP | Descripción |
|---|---|---|
| 25 M☉ | ~7 Myr | Muy masiva, vida muy corta |
| 15 M☉ | ~11 Myr | Supergigante |
| 10 M☉ | ~20 Myr | Estrellas tipo O/B |
| 8 M☉ | ~35 Myr | Tipo B |
| 6 M☉ | ~65 Myr | Tipo B/A |
| 5 M☉ | ~95 Myr | Tipo A |
| 4 M☉ | ~180 Myr | Tipo A/F |
| 3.5 M☉ | ~270 Myr | Tipo F |
| 3 M☉ | ~400 Myr | Tipo F |
| 2.5 M☉ | ~630 Myr | Tipo F/G |
| 2.2 M☉ | ~850 Myr | Tipo G |
| 2.0 M☉ | ~1,100 Myr | Tipo G |
| 1.7 M☉ | ~1,700 Myr | Tipo G |
| 1.5 M☉ | ~2,400 Myr | Tipo G/K |
| 1.2 M☉ | ~4,900 Myr | Tipo K |
| 1.0 M☉ | ~10,000 Myr | Sol (Tipo G2V) |
| 0.9 M☉ | ~14,000 Myr | Tipo K |
| 0.8 M☉ | ~21,000 Myr | Tipo K |
| 0.7 M☉ | ~32,000 Myr | Tipo K/M |
| 0.5 M☉ | ~80,000 Myr | Tipo M |
| 0.3 M☉ | ~200,000 Myr | Enana M |
| 0.1 M☉ | >1,000,000 Myr | Enana M tardía |
Durante esa fase la estrella permanece en una posición casi fija en el CMD. Cuando agota el hidrógeno la estrella ‘se mueve’ hacia arriba y a la derecha en el diagrama, hacia las gigantes rojas.
Si las estrellas no naciesen todas en mismo momento, veríamos que en el rango de las estrellas mass masivas (entre 3 y 4 M☉) habría algunas que ya salieron de la secuencia principal y otras más jóvenes que estarían aún en la secuencia principal: algunas ya tendrían consumido su combustible, y otras aún estarían en esa fase. Pero no vemos eso, en la parte superior izquierda del diagrama todas las estrellas se movieron hacia la fase de gigantes rojas.
La metalicidade similar de las estrellas identificadas como pertenicentes al cúmulo también se explicaría por esta baja dispersión. Cuando se habla de metalicidad en composición estelar, se refiere siempre a la presencia de elementos más pesados que el Helio (Fe, C, O…). La distinta metalicidad tiene efectos en la opacidad: a mayor metalicidad, mayor opacidad e por lo tanto temperatura más fría. Eso implica que dos estrellas de la misma masa y edad, estarían en la misma posición vertical pero no horizontal: la que tuviese mayor metalicidad sería más roja. En el diagrama veríamos gran dispersión horizontal. También tiene un efecto en la tasa a la que se consume el material en el núcleo, lo que daría lugar a distintas luminosidades.
Las estrellas del cúmulo se formaron de la misma nube molecular con la misma composición química, y la composición química es prácticamente idéntica para todas las estrellas.
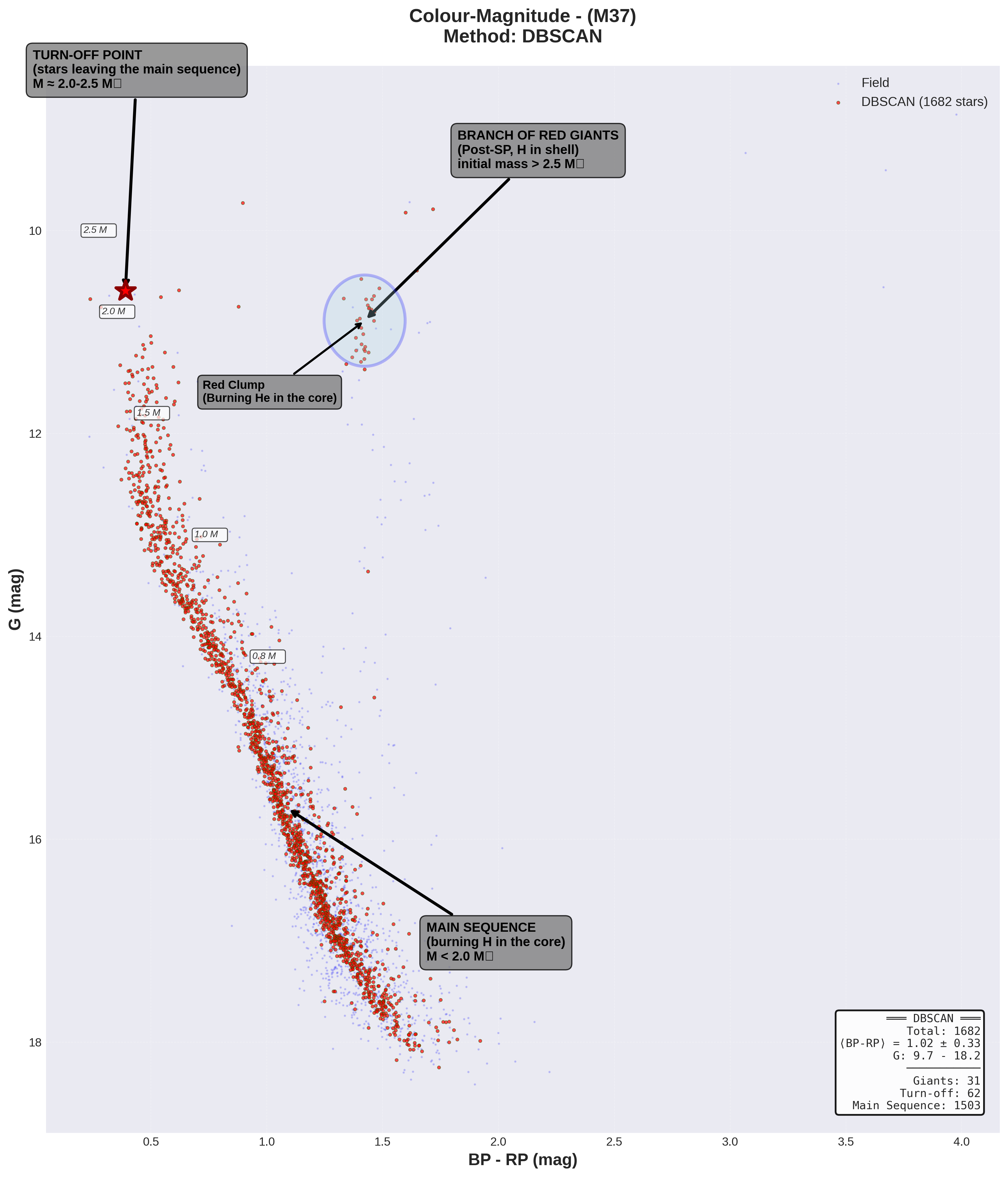
5.2. Turn-off visible
EL turn-off es una información clave que se puede extraer del diagrama CMD, ya que proporcionará la edad del cúmulo. Para entender por qué, en primer lugar vamos a mirar el diagrama. La secuencia principal diagonal es clara. Llega un punto donde se curva a la derecha, en BP-RP~0.4-0.5 e G~10.5-11 aproximadamente. Ese es el punto de turn-off, y puede definirse objetivamente como el punto más azul (menor BP-RP) y más brillante (menor G) de la secuencia principal antes de que se curve hacia la rama de las gigantes.
El turn-off marca el punto donde estrellas están agotando el hidróxeno en su núcleo y comiezan a evolucionar fuera de la secuencia principal. Su posición nos dirá la luminosidad, temperatura y por lo tanto masa, de las estrelas que están en esa fase. Con la tabla anterior, sabemos que edad tienen esas estrellas, porque sabemos cual es la edad en la que terminan su vida en la secuencia principal.
Para establecer a idade habrá que comparar el diagrama CMD con isocronas de modelos estelares, curvas del diagrama CMD para distintas edades del cúmulo. Existen varios modelos con bases de isocronas (PARSEC, MIST…) y en futuras entradas me dedicaré a investigar sobre ellas y como estimar la edad del cúmulo.
Por el momento, lo que sí vemos es que hai un turn-off point visible en el diagrama.
5.3. Rama de gigantes rojas clara
No diagrama CMD vemos también la rama de gigantes rojas en BP-RP entre 1.5 y 1.8 y G entre 10-11 aproximadamente. Habrá unas 30-35 estrellas en ese rango. Son estrellas que ya pasaron el turn-off, ya están evolucionando a giganges rojas. Son estrellas más frías pero siguen siendo muy brillantes. Que esta rama sea visible confirma que el cúmulo llegó a una edad suficiente cómo para que las estrellas más masivas hayan pasado a este punto.
5.4. Comparación Campo vs. Cúmulo
Al comparar las estrellas del cúmulo con las estrellas de campo en el diagrama también hay diferencias. Las estrellas del campo están más dispersas, y vemos como hay estrellas menos masivas en la rama camino a las gigantes y como la dispersión en la secuencia principal es más elevada, lo que sugiere múltiples edades, metalicidades y distancias.
Conclusión
Como conclusión a todo el proyecto, puedo decir que DBSCAN identificó correctamente el cúmulo M37. Esto será confirmado con los análisis con los otros dos métodos (HDBSCAN y GMM). Una vez confirmados los miembros, comenzaré los estudios de edad del cúmulo, análisis de función de masa inicial, binarias no resueltas y determinación de metalicidad.
Y personalmente, este proceso aportou gran cantidad de los objetivos del proyecto. Para interpretar los resultados tuve que leer publicaciones científicas sobre análisis de pertenencia, literatura académica sobre formación y evolución estelar, recuperar conceptos sobre luminosidad, temperatura, masa, fusión nuclear… Fue realmente gratificante.
Las dos siguientes entradas repetirán este proceso con los otros dos métodos, y finalmente el análisis comparativo de los 3 con estudios ya publicados sobre este mismo cúmulo.