Análise de pertenza do cúmulo M37 II - DBSCAN
Continuamos coa análise de pertenza para as estrelas do cúmulo M37, probando varios algoritmos, axustando parámetros e comparando os resultados coa literatura dispoñible. Nesta entrada centrarémonos en perfeccionar a análise con DBSCAN e analizar os seus resultados
Análise de pertenza con DBSCAN
Introducción
Na primeira parte vimos cómo facer unha análise básica de pertenza a un cúmulo aberto a partir dos datos descargados de Gaia para unha rexión dada. Nesta ocasión, imos facer esa análise moito máis rigurosa, usando varios algoritmos (DBSCAN, HDBSCAN e GMM), comparando os resultados entre eles e coa literatura dispoñible.
Buscando literatura atopo que M37 é un cúmulo bastante estudiado e que me permite comparar os resultados obtidos e validar o meu proxecto.
Coma nos artigos previos, os datos que usarei son descargados de Gaia DR3 (Gaia Collaboration, Vallenari, A., et al. (arXiv) (ADS)). A base de datos Gaia DR3 é a terceira release de datos e proporciona uns 1.81 mil millóns de obxectos, dos cales 1.47 mil millóns teñen os datos completos de astrometría e fotometría. En particular, os datos de paralaxe e movementos propios con altísima precisión serán usados aquí para a análise de pertenza.
A descripción dalgúns dos datos de Gaia é importante resaltala nalgún momento desta serie de artigos, e probablemente sexa merecedor dun artigo exclusivo.
Segundo a literatura atopada ou a propia páxina de SIMBAD para M37 os datos principáis do cúmulo son:
| RA (α) | Dec (δ) | pmra (μ_α) (mas/yr) | pmdec (μ_δ) (mas/yr) | parallax (π) (mas) |
|---|---|---|---|---|
| 88.074 | 32.545 | 1.924 ± 0.06 | -5.648 ± 0.05 | 0.666 ± 0.07 |
Destes datos partiremos para facer a descarga e filtrado de datos de Gaia e para comparar os datos obtidos como resultado.
Neste artigo compararemos 3 algoritmos de clasificación non supervisada (DBSCAN, HDBSCAN e GMM). Os 3 métodos son ampliamente utilizados en distintos artigos que abordan o problema da pertenza en cúmulos abertos. Outros artigos usan tamén outros algoritmos de clasificación supervisada como K-means, pero eu decidín descartalos polo momento, pois require de ter datos xa etiquetados para o entrenamento do modelo.
Descarga de datos de Gaia DR3
Para a descarga de datos de Gaia DR3 sigo o mesmo método que xa usei anteriormente cos seguintes parámetros:
RA (α): 88.074Dec (δ): 32.545search_radius: 1.5º
A elección de 1.5º pretende recuperar os datos non só de estrelas do centro do cúmulo, senon tamén as estrelas da coroa cercana e incluso algunha das estrelas evaporándose. Un radio máis grande podería ser adecuado para un estudo máis completo que inclúa as estructuras de marea do cúmulo. Non o farei neste momento, pero sí queda anotado como unha funcionalidad a selección do radio de búsqueda para incorporar en versións posteriores do código.
Tamén se inclúen os filtros estándar sobre os datos de Gaia:
FROM gaiadr3.gaia_source
WHERE 1=CONTAINS(
POINT('ICRS', ra, dec),
CIRCLE('ICRS', {cluster_ra}, {cluster_dec}, {search_radius})
)
AND parallax IS NOT NULL
AND parallax/parallax_error > 5
AND pmra IS NOT NULL
AND pmdec IS NOT NULL
AND ruwe < 1.4
AND phot_g_mean_mag < 20
Con estes datos a consulta a Gaia devolve 53.109 estrelas, con esta estadística básica:
Número de estrelas: 53109Paralaxe medio: 0.84 ± 0.88 masμ_α medio: 1.19 ± 5.32 mas/yrμ_δ medio: -4.55 ± 7.60 mas/yr
Filtrado dos datos descargados
Aquí decidín aplicar un filtro antes de aplicar os algoritmos de clasificación. Está bastante claro que nesta consulta hai moitas estrelas no mesmo campo de visión que non pertencen ao cúmulo. Pensemos agora que o cúmulo son precisamente estrelas que naceron na mesma zona e que se moven máis ou menos do mesmo xeito (con certa dispersión, por suposto). Para reducir o procesamento posterior e ir eliminando erros, vou filtrar os datos a partir do coñecemento que xa existe sobre o cúmulo M37. A valores de paralaxe e dos movementos propios dos membros do cúmulo teñen que estar nun valor cercano ao xa coñecido. Se filtramos os datos preto deses valores coñecidos e eliminamos os restantes, iremos afinando. ¿Cómo decidir os valores para filtrar? Considero o seguinte: cando decido un rango para o filtrado debo ter en conta que a Dispersión Total nos valores dos membros estará composta por:
**Dispersión total** = **dispersión intrínseca** + **erros de medida**
Dispersión instrínseca: non todas as estrelas do cúmulo se moven igual. Hai unha dispersión de velocidades que se poden deber principalmente a interaccións gravitatorias internas entre sí, encontros cercanos entre dúas estrelas, estrelas binarias que crean movementos ao orbitar entre elas ou estrelas que escapan do cúmulo con velocidades anómalas. Estas dispersións nas velocidades pódese estimar aproximadamente en:
- Cúmulos xoves (<100 Myr): σ_v ~ 0.5-1.5 km/s
- Cúmulos intermedios (100-500 Myr): σ_v ~ 0.3-1.0 km/s
- Cúmulos vellos (>500 Myr): σ_v ~ 0.2-0.8 km/s
A idade estimada de M37 é de 500Myr, e escollerei un rango algo amplio. Se inclúo estrelas de máis, agardo que os algoritmos de clustering filtren as estrelas que non pertenzan. O rango fixado no filtro é de σ_v ~ 0.5-1.0 km/s, que se pode traducir a mas/yr coa fórmula:
μ [mas/yr] = (v_transversal [km/s] / d [pc]) × 211.09A distancia estimada de M37 é de 1500pc, có que os valores do rango serían:
σ_μ = (0.5 km/s / 1500 pc) × 211.09 = 0.070 mas/yr (mínimo) σ_μ = (1.0 km/s / 1500 pc) × 211.09 = 0.141 mas/yr (máximo)É dicir, engadiría unha dispersión intrínseca σ_μ ~0.07 - 0.14 mas/yr.
Erro de medida de Gaia Os erros de medida de Gaia teñen que ver con varios factores: magnitude (estrelas máis débiles teñen maior erro), rexións do ceo con maior ou menor densidade de estrelas, número de observacións… Os erros típicos por magnitude son:
Magnitude G Erro Descripción G < 14 error_μ ~ 0.02-0.05 mas/yr estrelas brilantes 14 < G < 16 error_μ ~ 0.05-0.15 mas/yr estrelas intermedias 16 < G < 18 error_μ ~ 0.15-0.50 mas/yr estrelas débiles De novo, vou escoller un rango amplio: σ_error ~ 0.10-0.25 mas/yr tendo en conta que as estrelas que máis contribúen ao cúmulo están no rango G=12-17.
Á hora de combinar erros:
σ_total = √(σ_intrínseca² + σ_error²)
así que a dispersión total esperada é de ~0.2 - 0.3 mas/yr
- Marxe de seguridade Na práctica hai outras causas que poden afectar á dispersión do cúmulo. Unha regla empírica robusta é usar ±3σ a ±5σ alrededor do valor esperado:
±3σ → captura 99.7% dunha distribución normal ±4σ → captura 99.99% ±5σ → moi conservadorPrefiro ser conservador, e usar 5σ, o que nos daría para μ_α e para μ_δ unha marxe de σ_seguridade 1.25mas/yr.
En global, quédome cun rango nos movementos propios de rango μ_α de 0.7 a 3.0mas/yr e rango μ_δ de -7.0 a -4.0
- Límites na paralaxe Para filtrar a paralaxe e quedarnos dentro duns límites razonables que inclúan as estrelas do cúmulo e minimicen as estrelas de campo, teño en conta os valores estimados na literatura. A paralaxe estimada de M37 é de 0.666mas (distancia ~1500pc). A dispersión típica dun cúmulo aberto está entre os 10-50pc, que a unha distancia aproximada de 1500pc correspondería a unha marxe de paralaxe de ±0.01-0.05 mas. Engadimos unha marxe de erro na medida de Gaia (~0.05-0.10mas). Así que sendo conservadores, para non excluir estrelas do cúmulo no filtro, establezo un rango na paralaxe de 0.50-0.85mas.
Ao aplicar estes límites sobre os datos descargados de Gaia, obteño:
- `Número de estrelas`: **3377**
- `Paralaxe medio`: **0.67 ± 0.08 mas**
- `μ_α medio`: **1.86 ± 0.45 mas/yr**
- `μ_δ medio`: **-5.50 ± 0.62 mas/yr**
E como último paso fago unha normalización dos datos, para levalos todos a unha escala similar e que uns valores máis altos nun dos parámetros non dominen a análise.
Análise de pertenencia con DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) é un algoritmo que agrupa puntos baseándose na súa densidade local. O algoritmo ten dous parámetros principais:
eps: a distancia máxima entre dous puntos para consideralos veciños.min_samples: o número mínimo de puntos necesarios para formar un grupo denso.
DBSCAN é especialmente bo para cúmulos porque:
- Non asume que os grupos teñen forma esférica
- Pode identificar puntos como “ruído” (estrelas do campo)
- Non necesita saber de antemán cantos cúmulos hai
O certo é que non atopei polo momento un método para decidir cales son os valores óptimos para cada cúmulo, porque sí afectan ao resultado do algoritmo, e non parecen comportarse igual en cada cúmulo. Para o meu caso, despois de varias probas quedo con estes valores:
eps: 0.3min_samples: 20
Con estes valores obteño os seguintes resultados:
Número de cúmulos identificados: 1Estrelas clasificadas como ruido (campo): 1773Estrelas clasificadas no cúmulo principal1689Paralaxe: 0.67±0.05masμ_α: 1.88±0.15mas/yrμ_δ: -5.62±0.15mas/yr
Eses valores son extraordinariamente coincidentes con outros estudios (XXXXXXXXXXX) e cos propios datos de SIMBAD. Algunhas gráficas para ver o resultado:
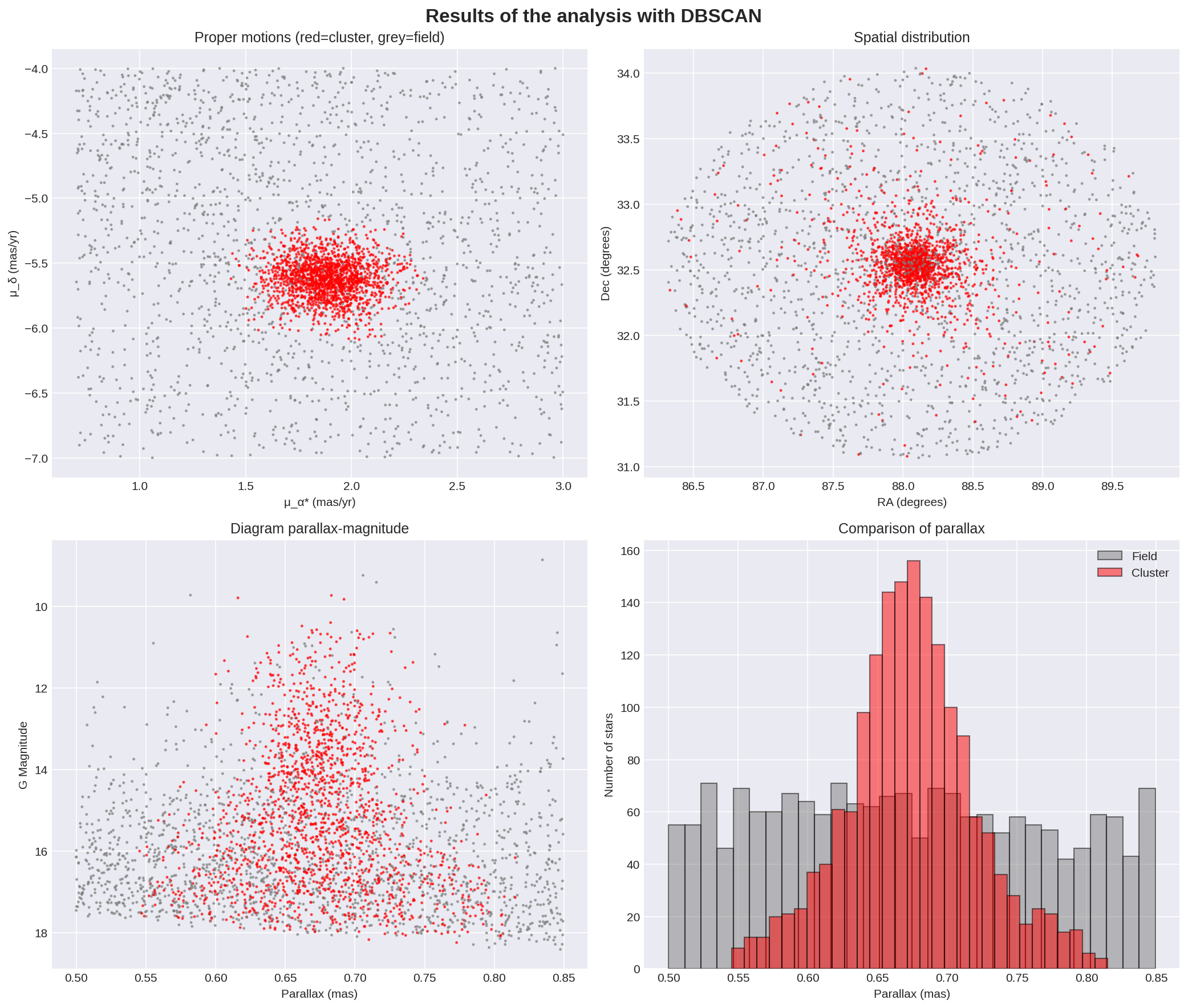
Estes 4 gráficos permiten verificar se a clasificación é consistente co coñecemento actual do cúmulo ou se hai algún dato que faga replantexar os parámetros do algoritmo.
Diagrama de movementos propios O diagrama de movementos propios é quizáis o máis importante: as estrelas do cúmulo naceron xuntas e viaxan xuntas polo espacio, polo que formarán un grupo compacto neste diagrama. O campo estelar está composto por estrelas de diferentes idades, distancias e órbitas galácticas, polo que aparecerá espallado. A separación clara entre estes dous grupos é a que fai posible a análise de pertenza. No diagrama xerado vese claramente como DBSCAN identificou correctamente o núclo do cúmulo e sen contaminiación significativa no espacio cinemático. O cúmulo en vermello é moi compacto centrado en (μ_α* ≈ 1.9, μ_δ ≈ -5.6). As estrelas de campo en gris están espalladas por todo o espacio. Non hai solapamento entre ambos.
Distribución espacial A distribución que se amosa na gráfica xerada é consistente co agardado: un núcleo central centrado en ~(88.0°, 32.7°) e radio ~0.3-0.4 grados. Non se aprecian subestructuras nen múltiples núcleos.
Diagrama Paralaxe-Magnitude Neste diagrama amósase a relación entre a magnitude absoluta dos membros vs distancia (paralaxe). Dado que as estrelas do cúmulo están á mesma distancia, agardamos ver unha columna vertical centrada en 0.67mas con estrelas de todas as magnitudes. Na parte superior estarían as estrelas máis brilantes (xigantes, estrelas masivas) e na parte inferior as estrelas máis débiles (enanas de baixa masa). Os datos observados son de novo coherentes co agardado: hai unha columna centrada en 0.67mas cun andho de ±0.03-0.04 mas aproximadamente. A partir destes datos poderíase obter a profundidade do cúmulo, que pode estar no entorno dos 50pc.
Histograma de paralaxes Este diagrama amosa o nº de estrelas vs paralaxe. Agardaríamos ter unha distribución gaussiana centrada en 0.67mas, pois as estrelas do cúmulo deberían estar todas á mesma distancia aproximadamente, e con máis concentración no centro do cúmulo. O que vemos é un pico central en ~0.67 mas, cunha altura de ~155 estrellas/bin. A forma é unha gaussiana e o ancho a media altura é de ~0.04 mas (0.65-0.69 mas).
Análise de pertenencia con HDBSCAN
…
Análise de pertenencia con GMM
…
Análise comparativo
…