Análise de pertenza do cúmulo M37 - II
Continuamos coa análise de pertenza para as estrelas do cúmulo M37, probando varios algoritmos, axustando parámetros e comparando os resultados coa literatura dispoñible.
Análise de pertenza
Introducción
Na primeira parte vimos cómo facer unha análise básica de pertenza a un cúmulo aberto a partir dos datos descargados de Gaia para unha rexión dada. Nesta ocasión, imos facer esa análise moito máis rigurosa, usando varios algoritmos (DBSCAN, HDBSCAN e GMM), comparando os resultados entre eles e coa literatura dispoñible.
Buscando literatura atopo que M37 é un cúmulo bastante estudiado e que me permite comparar os resultados obtidos e validar o meu proxecto. Na
Coma nos artigos previos, os datos que usarei son descargados de Gaia DR3 (Gaia Collaboration, Vallenari, A., et al. (arXiv) (ADS)). A base de datos Gaia DR3 é a terceira release de datos e proporciona uns 1.81 mil millóns de obxectos, dos cales 1.47 mil millóns teñen os datos completos de astrometría e fotometría. En particular, os datos de paralaxe e movementos propios con altísima precisión serán usados aquí para a análise de pertenza.
Segundo a propia ESA os datos liberados como Gaia Early Data Release 3 (Gaia EDR3) comprenden:
- A solución astrométrica completa —posicións no ceo (α, δ), paralaxe e movemento propio— para ao redor de 1460 millóns (1,46 × 109) de fontes, cunha magnitude límite de aproximadamente G ≈ 21 e un límite de brillo de aproximadamente G ≈ 3. A solución astrométrica vai acompañada dalgúns novos indicadores de calidade, como RUWE, e descritores de imaxes de fontes.
- A solución astrométrica completa realizouse como solución de 5 parámetros para 585 millóns de fontes e como solución de 6 parámetros para 882 millóns de fontes. Na solución de 6 parámetros, a cantidade axustada adicional é o denominado pseudocolor, que tivo que incluírse para as fontes sen información de cor de alta calidade.
- Ademais, solucións de dous parámetros (posicións no ceo (α, δ)) para ao redor de 344 millóns de fontes adicionais.
- Magnitudes G para ao redor de 1806 millóns de fontes (co problema coñecido presente en EDR3 corrixido en Gaia DR3).
- Magnitudes GBP e GRP para ao redor de 1540 millóns e 1550 millóns de fontes, respectivamente.
Esta descripción dalgúns dos datos de Gaia era importante resaltala nalgún momento desta serie de artigos, e probablemente sexa merecedor dun artigo exclusivo.
Segundo a literatura atopada ou a propia páxina de SIMBAD para M37 os datos principáis do cúmulo son:
| RA (α) | Dec (δ) | pmra (μ_α) (mas/yr) | pmdec (μ_δ) (mas/yr) | parallax (π) (mas) |
|---|---|---|---|---|
| 88.074 | 32.545 | 1.924 ± 0.06 | -5.648 ± 0.05 | 0.666 ± 0.07 |
Destes datos partiremos para facer a descarga e filtrado de datos de Gaia e para comparar os datos obtidos como resultado.
Neste artigo compararemos 3 algoritmos de clasificación non supervisada (DBSCAN, HDBSCAN e GMM). Os 3 métodos son ampliamente utilizados en distintos artigos que abordan o problema da pertenza en cúmulos abertos. Outros artigos usan tamén outros algoritmos de clasificación supervisada como K-means, pero eu decidín descartalos polo momento, pois require de ter datos xa etiquetados para o entrenamento do modelo.
Descarga de datos de Gaia DR3
Para a descarga de datos de Gaia DR3 sigo o mesmo método que xa usei anteriormente cos seguintes parámetros:
RA (α): 88.074Dec (δ): 32.545search_radius:1.5º
A elección de 1.5º pretende recuperar os datos non só de estrelas do centro do cúmulo, senon tamén as estrelas da coroa cercana e incluso algunha das estrelas evaporándose. Un radio máis grande podería ser adecuado para un estudo máis completo que inclúa as estructuras de marea do cúmulo. Non o farei neste momento, pero sí queda anotado como unha funcionalidad a selección do radio de búsqueda para incorporar en versións posteriores do código.
Tamén se inclúen os filtros estándar sobre os datos de Gaia:
FROM gaiadr3.gaia_source
WHERE 1=CONTAINS(
POINT('ICRS', ra, dec),
CIRCLE('ICRS', {cluster_ra}, {cluster_dec}, {search_radius})
)
AND parallax IS NOT NULL
AND parallax/parallax_error > 5
AND pmra IS NOT NULL
AND pmdec IS NOT NULL
AND ruwe < 1.4
AND phot_g_mean_mag < 20
Con estes datos a consulta a Gaia devolve 53.109 estrelas, con esta estadística básica:
Número de estrelas: 53109Paralaxe medio: 0.84 ± 0.88 masμ_α medio: 1.19 ± 5.32 mas/yrμ_δ medio: -4.55 ± 7.60 mas/yr
Aquí decido aplicar un filtro antes de aplicar os algoritmos de clasificación. Está bastante claro que nesta consulta hai moitas estrelas no mesmo campo de visión que non pertencen ao cúmulo. Pensemos agora que o cúmulo son precisamente estrelas que naceron na mesma zona e que se moven máis ou menos do mesmo xeito (con certa dispersión, por suposto). Para reducir o procesamento posterior e ir eliminando erros, vou filtrar os datos a partir do coñecemento que xa existe sobre o cúmulo M37. A valores de paralaxe e dos movementos propios dos membros do cúmulo teñen que estar nun valor cercano ao xa coñecido. Se filtramos os datos preto deses valores coñecidos e eliminamos os restantes, iremos afinando. ¿Cómo decidir os valores para filtrar? Considero o seguinte: cando decido un rango para o filtrado debo ter en conta que a Dispersión Total nos valores dos membros estará composta por:
Dispersión total = dispersión intrínseca + erros de medida
Dispersión instrínseca: non todas as estrelas do cúmulo se moven igual. Hai unha dispersión de velocidades que se poden deber principalmente a interaccións gravitatorias internas entre sí, encontros cercanos entre dúas estrelas, estrelas binarias que crean movementos ao orbitar entre elas ou estrelas que escapan do cúmulo con velocidades anómalas. Estas dispersións nas velocidades pódese estimar aproximadamente en:
- Cúmulos xoves (<100 Myr): σ_v ~ 0.5-1.5 km/s
- Cúmulos intermedios (100-500 Myr): σ_v ~ 0.3-1.0 km/s
- Cúmulos vellos (>500 Myr): σ_v ~ 0.2-0.8 km/s
A idade estimada de M37 é de 500Myr, e escollerei un rango algo amplio. Se inclúo estrelas de máis, agardo que os algoritmos de clustering filtren as estrelas que non pertenzan. O rango fixado no filtro é de σ_v ~ 0.5-1.0 km/s, que se pode traducir a mas/yr coa fórmula:
μ [mas/yr] = (v_transversal [km/s] / d [pc]) × 211.09
A distancia estimada de M37 é de 1500pc, có que os valores do rango serían:
σ_μ = (0.5 km/s / 1500 pc) × 211.09 = 0.070 mas/yr (mínimo)
σ_μ = (1.0 km/s / 1500 pc) × 211.09 = 0.141 mas/yr (máximo)
É dicir, engadiría unha dispersión intrínseca σ_μ ~0.07 - 0.14 mas/yr.
- Erro de medida de Gaia Os erros de medida de Gaia teñen que ver con varios factores: magnitude (estrelas máis débiles teñen maior erro), rexións do ceo con maior ou menor densidade de estrelas, número de observacións… Os erros típicos por magnitude son:
| Magnitude G | Erro | Descripción |
|---|---|---|
| G < 14 | error_μ ~ 0.02-0.05 mas/yr | estrelas brilantes |
| 14 < G < 16 | error_μ ~ 0.05-0.15 mas/yr | estrelas intermedias |
| 16 < G < 18 | error_μ ~ 0.15-0.50 mas/yr | estrelas débiles |
De novo, vou escoller un rango amplio: σ_error ~ 0.10-0.25 mas/yr tendo en conta que as estrelas que máis contribúen ao cúmulo están no rango G=12-17.
Á hora de combinar erros:
σ_total = √(σ_intrínseca² + σ_error²)
así que a dispersión total esperada é de ~0.2 - 0.3 mas/yr
- Marxe de seguridade Na práctica hai outras causas que poden afectar á dispersión do cúmulo. Unha regla empírica robusta é usar ±3σ a ±5σ alrededor do valor esperado:
±3σ → captura 99.7% dunha distribución normal ±4σ → captura 99.99% ±5σ → moi conservadorPrefiro ser conservador, e usar 5σ, o que nos daría para μ_α e para μ_δ unha marxe de σ_seguridade 1.25mas/yr.
En global, quédome cun rango nos movementos propios de rango μ_α de 0.7 a 3.0mas/yr e rango μ_δ de -7.0 a -4.0
- Límites na paralaxe Para filtrar a paralaxe e quedarnos dentro duns límites razonables que inclúan as estrelas do cúmulo e minimicen as estrelas de campo, teño en conta os valores estimados na literatura. A paralaxe estimada de M37 é de 0.666mas (distancia ~1500pc). A dispersión típica dun cúmulo aberto está entre os 10-50pc, que a unha distancia aproximada de 1500pc correspondería a unha marxe de paralaxe de ±0.01-0.05 mas. Engadimos unha marxe de erro na medida de Gaia (~0.05-0.10mas). Así que sendo conservadores, para non excluir estrelas do cúmulo no filtro, establezo un rango na paralaxe de 0.50-0.85mas.
Ao aplicar este límite sobre os datos descargados de Gaia, obteño:
Número de estrelas: 3377Paralaxe medio: 0.67 ± 0.08 masμ_α medio: 1.86 ± 0.45 mas/yrμ_δ medio: -5.50 ± 0.62 mas/yr
A partir de ahí fago unha normalización dos datos, para levalos todos a unha escala similar e que uns valores máis altos nun dos parámetros non dominen a análise.
Análise de pertenencia con DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) é un algoritmo que agrupa puntos baseándose na súa densidade local. O algoritmo ten dous parámetros principais:
eps: a distancia máxima entre dous puntos para consideralos veciños.min_samples: o número mínimo de puntos necesarios para formar un grupo denso.
DBSCAN funciona como si esparcieras semillas en un campo y solo consideraras “grupos” aquellas zonas donde caen muchas semillas juntas. El parámetro eps define qué tan juntas deben estar las semillas para considerarlas vecinas, mientras que min_samples determina cuántas semillas necesitas en un área para considerar que hay un “grupo real” y no solo casualidad. La gran ventaja es que las estrellas aisladas (del campo) se marcan explícitamente como ruido (etiqueta -1), lo cual tiene mucho sentido astrofísico.
DBSCAN é especialmente bo para cúmulos porque:
- Non asume que os grupos teñen forma esférica
- Pode identificar puntos como “ruído” (estrelas do campo)
- Non necesita saber de antemán cantos cúmulos hai
O certo é que non atopei polo momento un método para decidir cales son os valores óptimos para cada cúmulo, porque sí afectan ao resultado do algoritmo, e non parecen comportarse igual en cada cúmulo. Para o meu caso, despois de varias probas quedo con estes valores:
eps: 0.3min_samples: 20
Con estes valores obteño os seguintes resultados:
- Número de cúmulos identificados: 1
- Estrelas clasificadas como ruido (campo): 1773
- Estrelas en cúmulos: 1689
- O cúmulo principal ten 1689 estrelas
- Paralaxe: 0.67±0.05mas
- μ_α*: 1.88±0.15mas/yr
- μ_δ: -5.62±0.15mas/yr
Eses valores son extraordinariamente coincidentes con outros estudios (XXXXXXXXXXX) e cos propios datos de SIMBAD. Algunhas gráficas para ver o resultado:
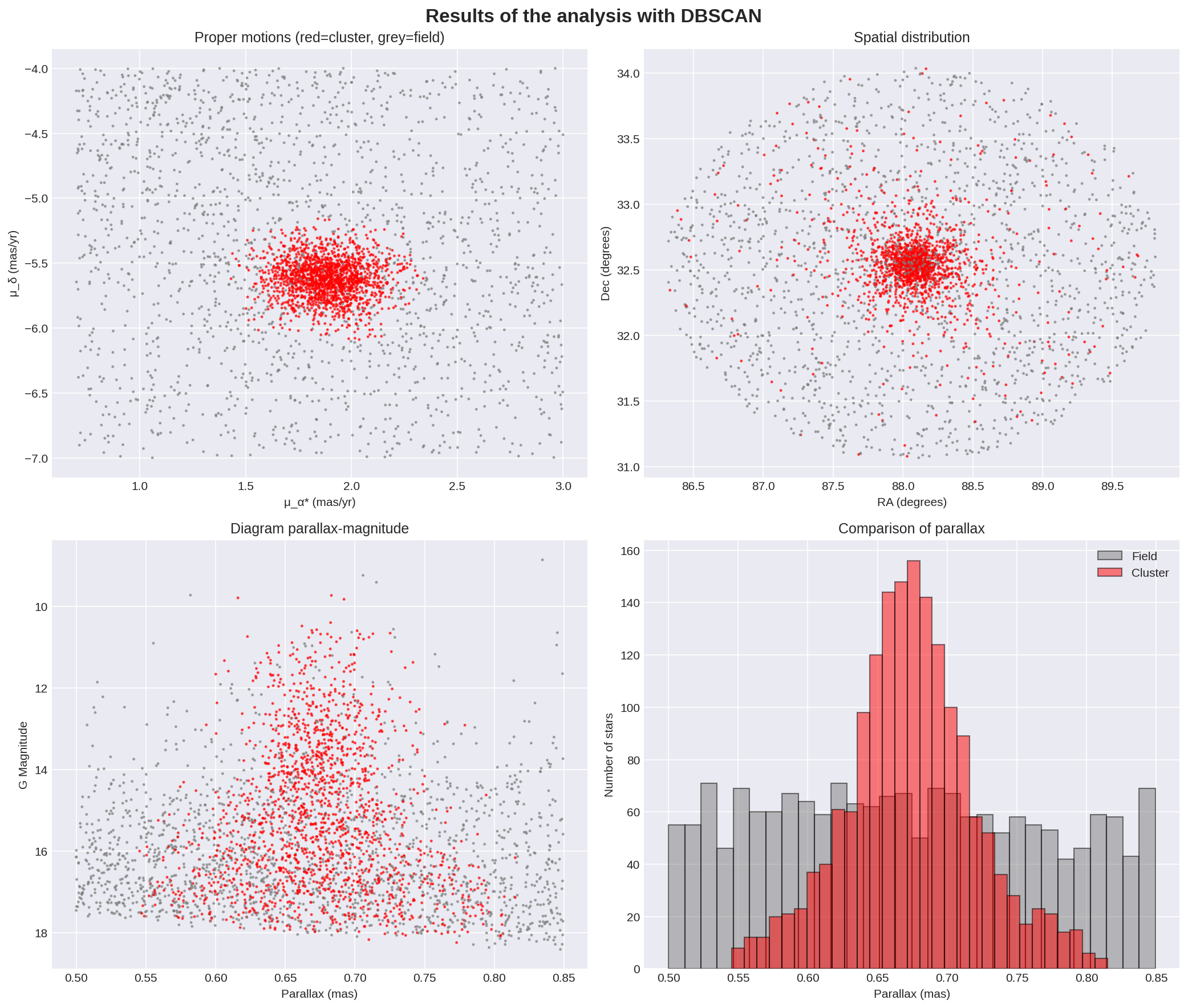
Estes 4 gráficos permiten verificar se a clasificación é consistente co coñecemento actual do cúmulo ou se hai algún dato que faga replantexar os parámetros do algoritmo.
- Diagrama de movementos propios O diagrama de movementos propios é quizáis o máis importante: as estrelas do cúmulo naceron xuntas e viaxan xuntas polo espacio, polo que formarán un grupo compacto neste diagrama. O campo estelar está composto por estrelas de diferentes idades, distancias e órbitas galácticas, polo que aparecerá espallado. A separación clara entre estes dous grupos é a que fai posible a análise de pertenza.
No diagrama xerado vese claramente como DBSCAN identificou correctamente o núclo do cúmulo e sen contaminiación significativa no espacio cinemático. O cúmulo en vermello é moi compacto centrado en (μ_α* ≈ 1.9, μ_δ ≈ -5.6). As estrelas de campo en gris están espalladas por todo o espacio. Non hai solapamento entre ambos.
Distribución espacial A distribución que se amosa na gráfica xerada é consistente co agardado: un núcleo central centrado en ~(88.0°, 32.7°) e radio ~0.3-0.4 grados. Non se aprecian subestructuras nen múltiples núcleos.
Diagrama Paralaxe-Magnitude Neste diagrama amósase a relación entre a magnitude absoluta dos membros vs distancia (paralaxe). Dado que as estrelas do cúmulo están á mesma distancia, agardamos ver unha columna vertical centrada en 0.67mas con estrelas de todas as magnitudes. Na parte superior estarían as estrelas máis brilantes (xigantes, estrelas masivas) e na parte inferior as estrelas máis débiles (enanas de baixa masa).
Os datos observados son de novo coherentes co agardado: hai unha columna centrada en 0.67mas cun andho de ±0.03-0.04 mas aproximadamente. A partir destes datos poderíase obter a profundidade do cúmulo, que pode estar no entorno dos 50pc.
- Histograma de paralaxes Este diagrama amosa o nº de estrelas vs paralaxe. Agardaríamos ter unha distribución gaussiana centrada en 0.67mas, pois as estrelas do cúmulo deberían estar todas á mesma distancia aproximadamente, e con máis concentración no centro do cúmulo.
O que vemos é un pico central en ~0.67 mas, cunha altura de ~155 estrellas/bin. A forma é unha gaussiana e o ancho a media altura é de ~0.04 mas (0.65-0.69 mas).

M37 é o cúmulo máis rico da constelación de Auriga, con outros dous membros moi interesantes, M36 e M38. Según algunhas fontes é coñecido como “Cúmulo da sal e pementa”. Segundo algúns estudios está a aproximadamente 4.500 anos-luz de distancia. A luz que vin esta fin de semana saiu máis ou menos cando se estaba a levantar o Dolmen de Dombate, a catedral do megalitismo no noroeste de España, e un dos meus lugares predilectos.
Orixe e formación dos cúmulos abertos
Compre explicar brévemente a orixe dun cúmulo aberto. Un cúmulo aberto é un grupo de estrelas que se formaron xuntas a partir da mesma nube molecular de gas e polvo. Coñecense tamén como ‘cúmulos galácticos’ porque atópanse no plano das galaxias espiráis, como a nosa Vía Láctea, onde a formación estelar é máis activa. As estrelas dos cúmulos abertos soen ser xóvenes (< 1.000 millóns de anos de idade), soen estar compostos dende poucas decenas ata uns poucos miles de estrelas. A súa forma é irregular, e as súas estrelas están ligadas gravitatoriamente.
O proceso de formación dun cúmulo aberto empeza cunha gran nube molecular de gas e pó. Dentro desta nebulosa, a gravidade provoca que algunhas zonas se contraigan e colapsen. A medida que estas rexións se comprimen, a presión e a temperatura aumentan, o que desencadena as reaccións de fusión nuclear e o nacemento de novas estrelas. As estrelas recén formadas emiten unha gran cantidade de radiación e ventos estelares que empuxan o gas e o pó restantes cara o exterior. Este proceso disipa a nebulosa de orixen, deixando atrás o grupo de estrelas xóvenes que resultan visibles como un cúmulo aberto.
Debido a que as estrelas dun cúmulo abierto non están tan fortemente unidas pola gravidade como nos cúmulos globulares, a interacción gravitatoria con outras estrelas, nubes de gas ou o propio centro da galaxia fai que, co tempo, o cúmulo se disperse e as súas estrelas se separen.
Análise de pertenza
A análise de pertenza busca separar qué estrelas que realmente pertencen ao cúmulo das estrelas de campo que só están na mesma liña de visión por casualidade. As estrelas do cúmulo son estrelas que naceron xuntas, móvense xuntas e estan á mesma distancia. As estrelas de campo están a diferentes distancias e móvense aleatoriamente; non parecen estar relacionadas entre sí nin co resto das estrelas do cúmulo. Tendo isto en conta, usaremos 3 parámetros para facer a análise de pertenza:
pmRAepmDEC(movementos propios): as estrelas do cúmulo teñen movementos propios moi similares porque naceron da mesma nube molecular e manteñen velocidades similares, o cúmulo móvese coma un todo pola Galaxia.paralaxe: as estrelas do cúmulo están á mesma distancia polo que teñen paralaxes similares.
Para facer a análise usando algoritmos de clustering, podemos escoller entre varios. Un que usei no pasado en entornos de datos empresariais é K-means. Outro que se usa en este tipo de análise é DBSCAN. Vou usar este último por varios motivos: o principal diría que é que DBSCAN non precisa saber a priori cántos grupos ten que facer, se non que o descubre automáticamente. Dado que o propósito desta entrada é amosar unha posible aplicación dos datos de Gaia para analizar cúmulos abertos, non profundizarei moito máis comparando con outros métodos, ou mellorando a implementación deste algoritmo (algo que espero ir facendo máis adiante). Fai uns anos nun proxecto para unha empresa probei PyCaret para validar o resultado con distintos algoritmos, facer o axuste fino dos parámetros e orquestrar todo o pipeline en só 14 liñas de código. Espero revisalo próximamente neste contexto.
Descripción do procesado
O caderno Jupyter está no repositorio do proxecto.
Configuración do entorno
Realizarei o desenrolo usando Python no mesmo entorno virtual que creei na primeira entrada. Só hai que engadir a popular librería scikit-learn.
conda activate cluster_env
pip install scikit-learn
Obtención de datos
Datos básicos dende SIMBAD
Vou reaproveitar parte do código que fixen no primeiro caderno Jupyter. Primeiro, recupero os datos básicos (coordenadas, tamaño…) en SIMBAD. Con este resultado xa temos os datos necesarios para consultar en Gaia (coordenadas e tamaño). Ao executar a consulta en SIMBAD obteño:
Name: M 37Type: OpCRA: 88.077300ºDec: 32.543400ºPmRA: 1.924 (mas/yr)PmDec: -5.648 (mas/yr)galdim_majaxis: 19.299999237060547 (arcmin)galdim_minaxis: 19.299999237060547 (arcmin)Radius: 9.649999618530273 (arcmin)Parallax: 0.666 (mas)
Xa teño as coordenadas e o tamaño. Con iso imos lanzar a consulta á base de datos DR3 de Gaia. Hai que ter en conta neste momento que o tamaño máximo que estou collendo é o que devolve SIMBAD. Quizáis debería ampliar un pouco máis o radio de búsqueda para non deixar fora da consulta estrelas do cúmulo. O campo aparente que vin no ocular do telescopio sí me pareceu superior a 20 minutos de arco.
Consulta á base de datos DR3 de Gaia
Agora imos conectarnos á base de datos de Gaia e lanzar unha consulta a partir dos parámetros obtidos. Nesta ocasión aproveito para facer unha función que espero ir pulindo e reaproveitando máis adiante.
A consulta ADQL xa inclúe varios filtros de calidade:
parallax > 0: recupero só estrelas con paralaxe válidaparallax/parallax_error > 5: filtro só resultados con erro na paralaxe baixopmra_error IS NOT NULLepmdec_error IS NOT NULL: estrelas con erro reportado nos movementos propiosphot_g_mean_mag < 20: estrellas máis brilantes de magnitude 20ruwe < 1.4: estrellas con Renormalised Unit Weight Error <1.4 que garantiza eliminar estrelas binarias, astrometría aceptable…
E lanzo a consulta de forma sinxela, reaproveitando o código anterior. Esta consulta devolve un obxecto astropy.table.Table, que transformo nun Pandas Dataframe co método to_pandas().
A consulta devolve 1.783 estrelas nese campo de visión.
Algunhas visualizacións básicas
Agora fago algunha gráfica interesante que servirán en futuras análises dos cúmulos. Polo momento só de xeito ilustrativo:
- mapa celeste
- diagrama de movementos propios
- histograma de paralaxes
- diagrama color-magnitude
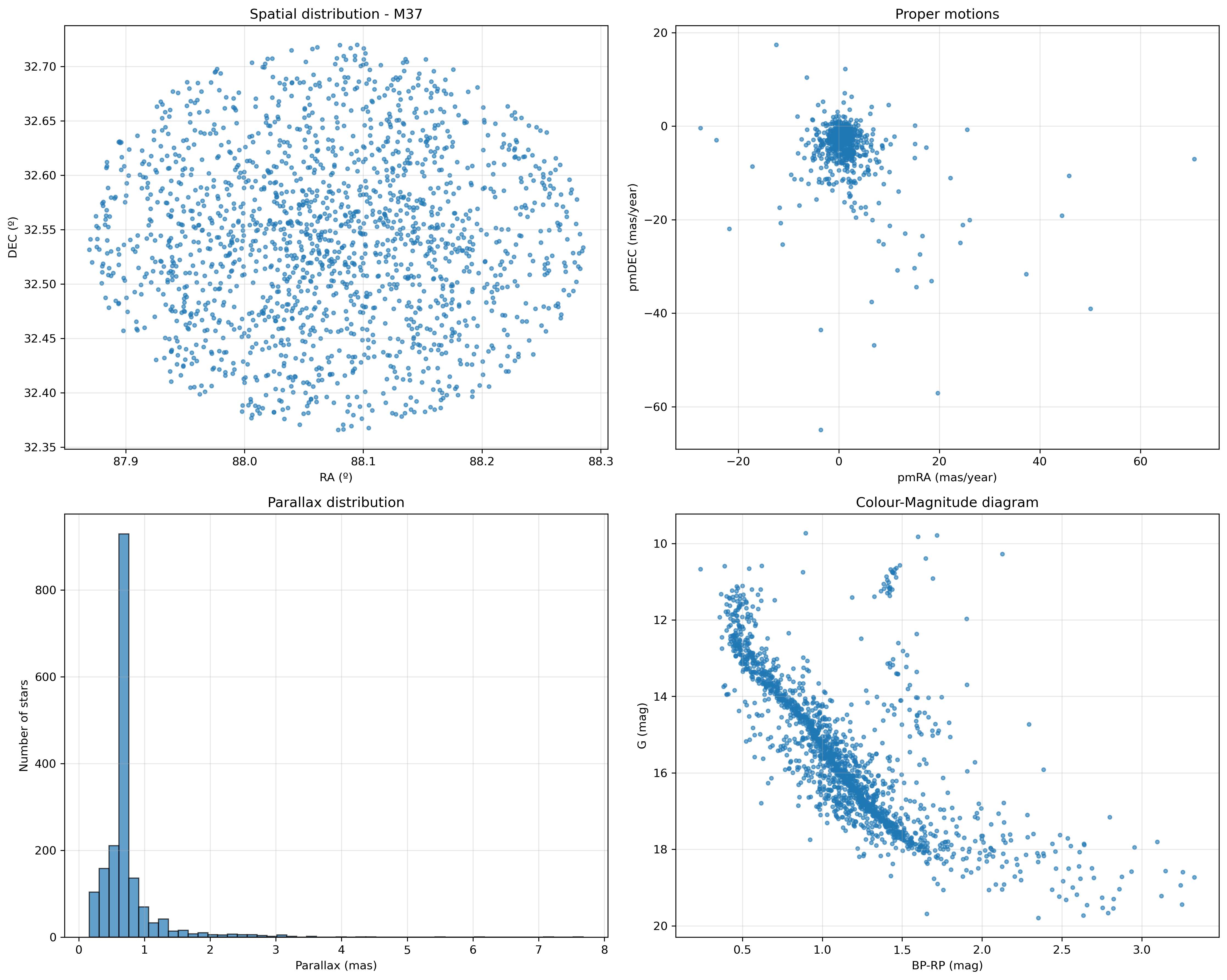
Tamén estiven a probar a conversión dos parámetros BP e RP a cores RGB, de xeito que poderíamos pintar a cor aproximada de cada estrela nestes gráficos:
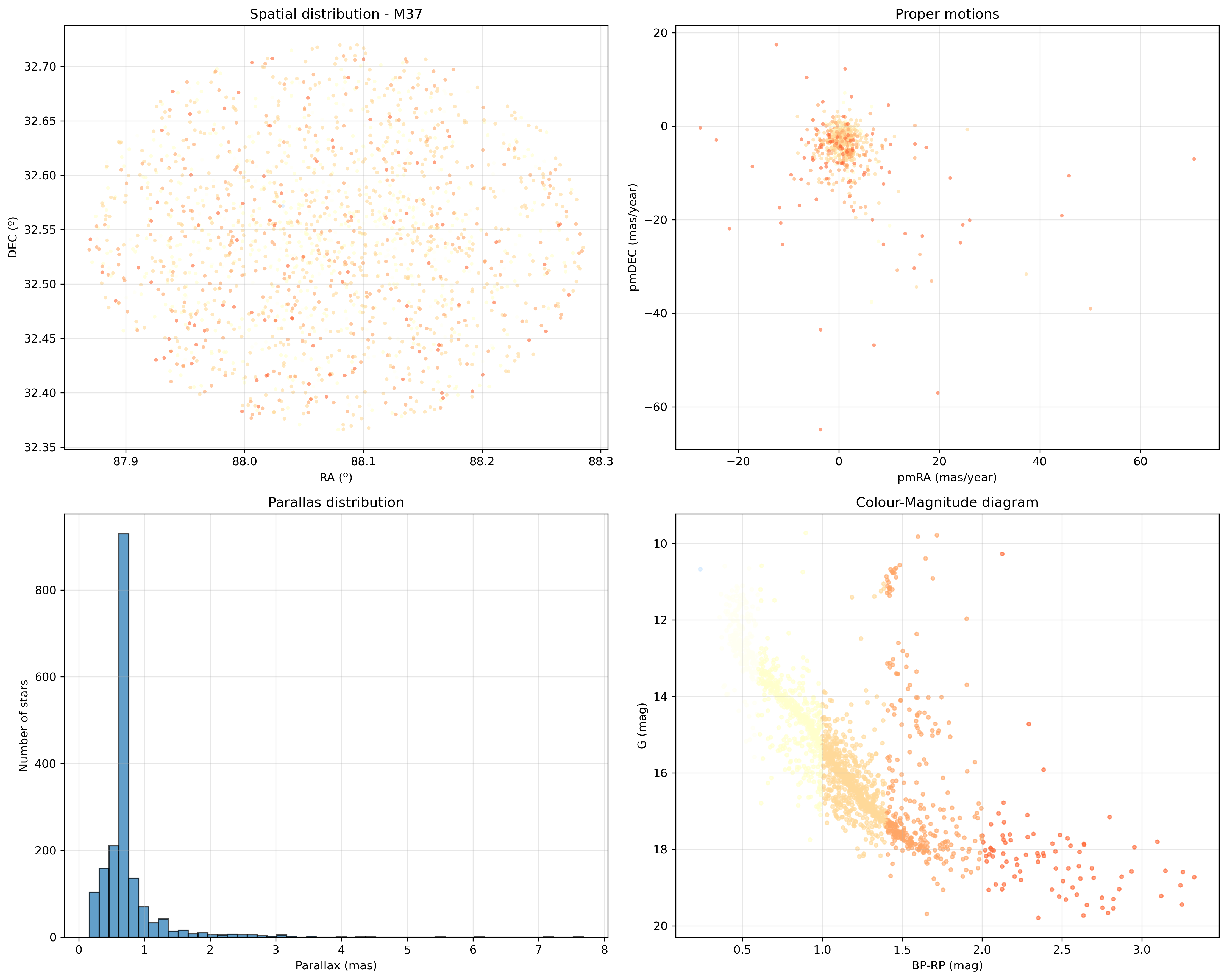
Na segunda parte profundizarei na información que se pode extraer de cada un destes gráficos.
Análise de membresía
Aquí ven a parte importante do proxecto de hoxe: usar algoritmos de clustering para determinar cales son as estrelas que pertencen ao cúmulo. Como comentaba na introducción, só probarei agora o algoritmo DBSCAN.
Creo unha función para aplicar o algoritmo. Os parámetros que vou usar son os movementos propios e a paralaxe. Como primeira aproximación creo que son os datos máis importantes e centrareime neles.
Seguindo os pasos habituais na aplicacións de algoritmos de clasificación, aplico StandardScaler para escalar os datos e evitar que un dos parámetros inflúa máis que o outro por ter valores maiores. Logo aplico o algoritmo sobre os datos. Usei uns parámetros que atopei en algunha lectura, pero que requerirían un fine tunning para obter os mellores resultados.
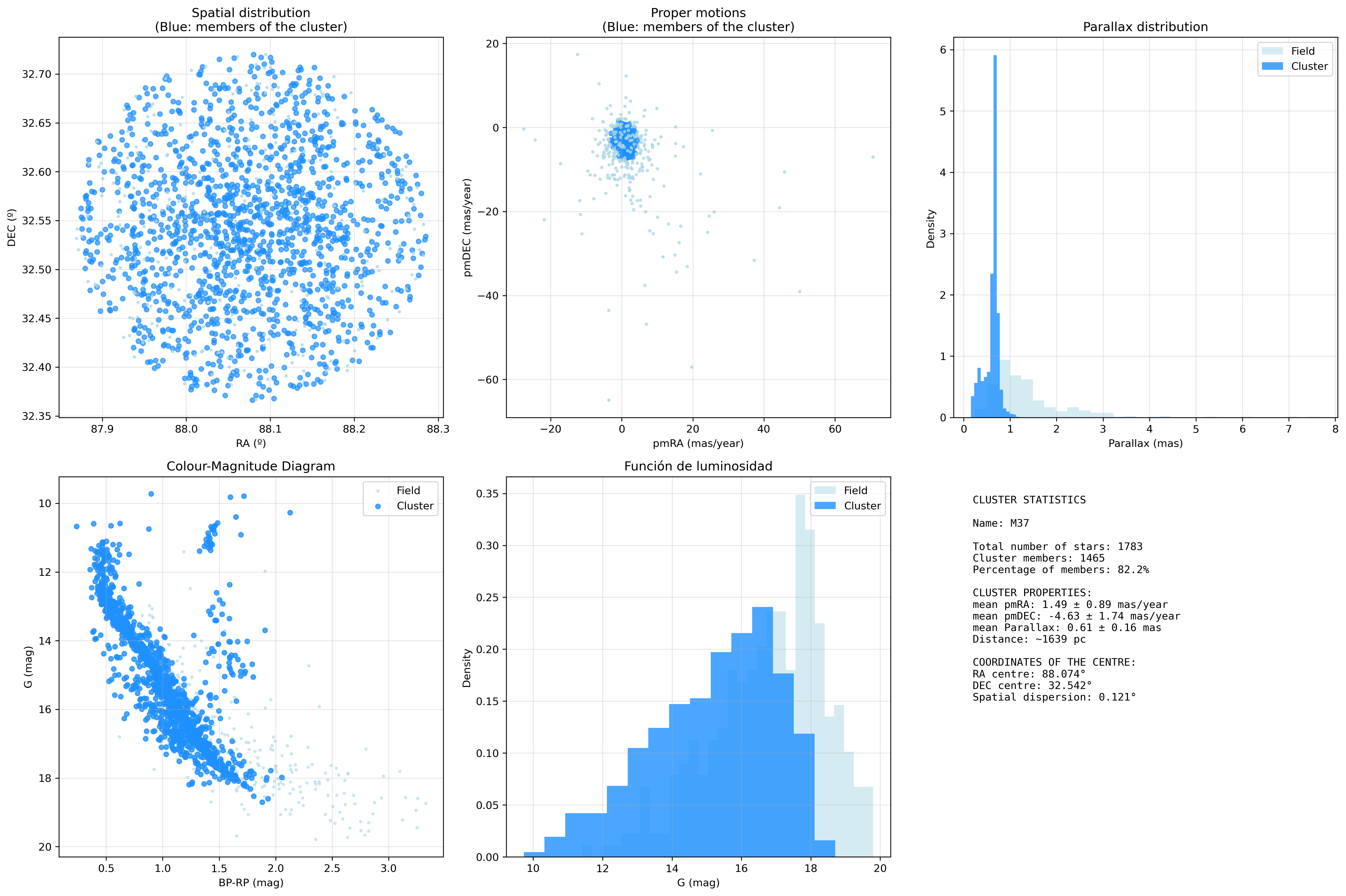
A saída final deste bloque de código é unha nova columna no DataFrame indicando se cada unha das estrelas descargadas é ou non é membro do cúmulo principal. E con isto obteño 1.465 estrelas pertencentes ao cúmulo e 318 identificadas como ruido.
Na seguinte entrada buscarei literatura sobre outras análises deste cúmulo para comparar e ver se a miña aproximación semella correcta.
Resultados
Agora temos un DataFrame con datos das estrelas pertencentes ao cúmulo con varios parámetros, dos que podemos sacar alguns resultados:
RA do centro: 88.074ºDEC do centro: 32.542ºmean pmRA: 1.49 ± 0.89 mas/anomean pmDEC: -4.63 ± 1.74 mas/anomean Parallax: 0.61 ± 0.016mean distance: ~ 1.639 pc
E finalmente, engadimos as mesmas visualizacións anteriores, pero marcando cales son as estrelas membros do cúmulo.
Conclusións e seguintes pasos
O presente exercició é só outra introducción para aprender a descargar e facer análise de datos dun cúmulo aberto cos datos dispoñibles en Gaia DR3. Este tipo de exercicios axudanme no proceso de descubrir todos os datos dispoñibles na base de datos de Gaia, qué atributos son os máis relevantes no estudo dos cúmulos abertos e cómo procesalos. Tamén, aínda que será descrito na parte II deste artigo, descubrir a literatura científica sobre este e outros cúmulos, aprender sobre os parámetros físicos que se teñen estudiado, e cales son as liñas de investigación abertas neste campo.
Con todo isto agardo ir avanzando en adquirir unha base sólida para profundizar nestes eido e desenrolar análises máis complexas.
Sobre a análise de M37, quedan abertos aínda bastantes puntos nos que espero traballar próximamente:
- Atopar literatura científica coa que poder comparar os resultados.
- Realizar fine tunning dos parámetros usados no algoritmo.
- Comparar os resultados con outros algoritmos para realizar a análise de pertenza.
Na seguinte entrada tentarei facer esta investigación, comparar os resultados obtidos con outros estudios publicados, e avanzar na interpretación física dos gráficos e da información relevante que se pode obter.